
Stable Diffusion Web UIの便利な拡張機能を紹介する記事です。
今回は画像からタグを抽出&キャプションデータの作成できる「tagger」をご紹介します。
taggerとは?
taggerは、画像からタグを抽出できる拡張機能です。
以下のように取り込んだ画像にどのタグがどのくらいの含まれているか、割合を調べることができます。
また複数の画像が入ったフォルダを指定すると、キャプションデータを作成することができ、さらにUI上で学習させるタグの調整も可能です。
学習させたいタグをクリックで選ぶだけなので、手動より遥かに効率がよくなります。
なお、キャプションデータの作成はできませんが、Stable Diffusion Web UIにデフォルトでタグを解析できる機能もあるので、こちらも参考にしてみてください。

taggerのインストール方法
Extensions→Install from URL→URL for~に以下のURLを入力して、Installボタンをクリックしてください。
https://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git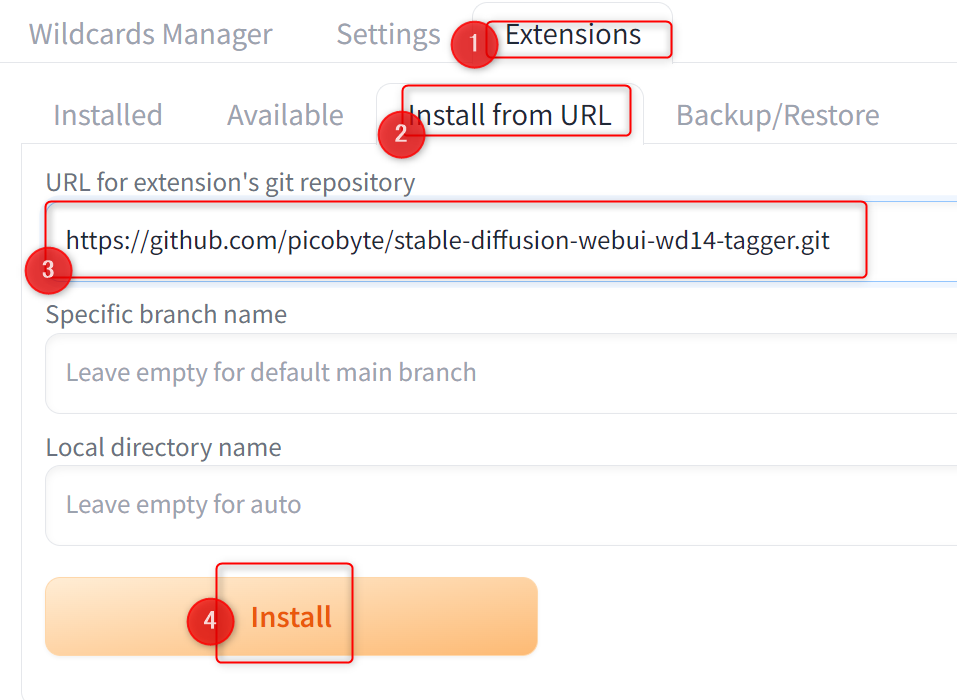
インストール後、リスタート、または再起動して、タブに「Taggar」が追加されていればインストールは完了です。
taggerの使い方
taggerの使い方は主に2つです。
- 1枚の画像からタグを解析する方法
- 複数の画像からキャプションデータを作る方法
1枚の画像からタグを解析する方法
まずはtaggerのタブを開き、Single processに画像を取り込んでください。

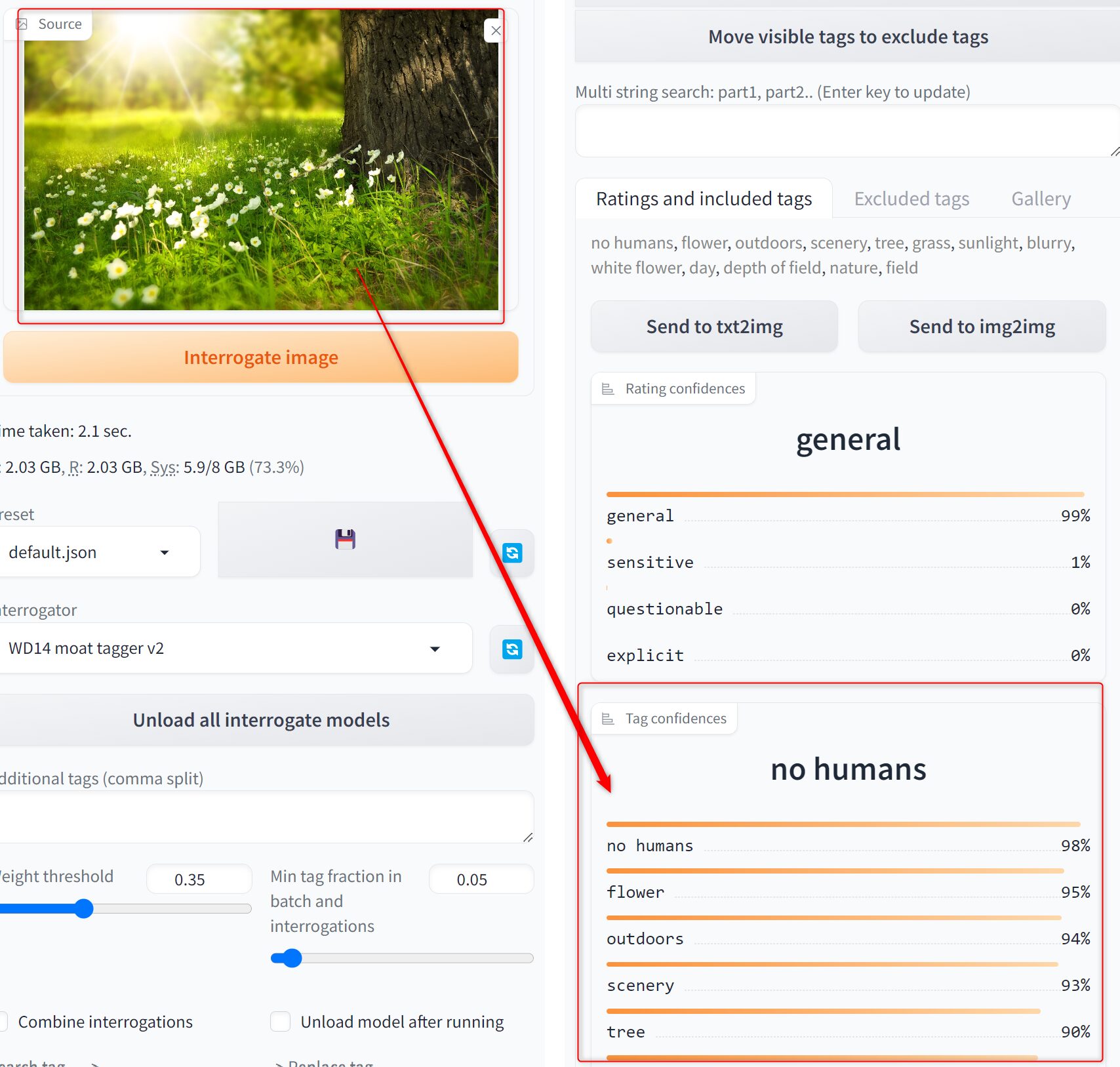
このまま「Interrogate image」を押すと解析が始まり、右側に解析結果がでます。
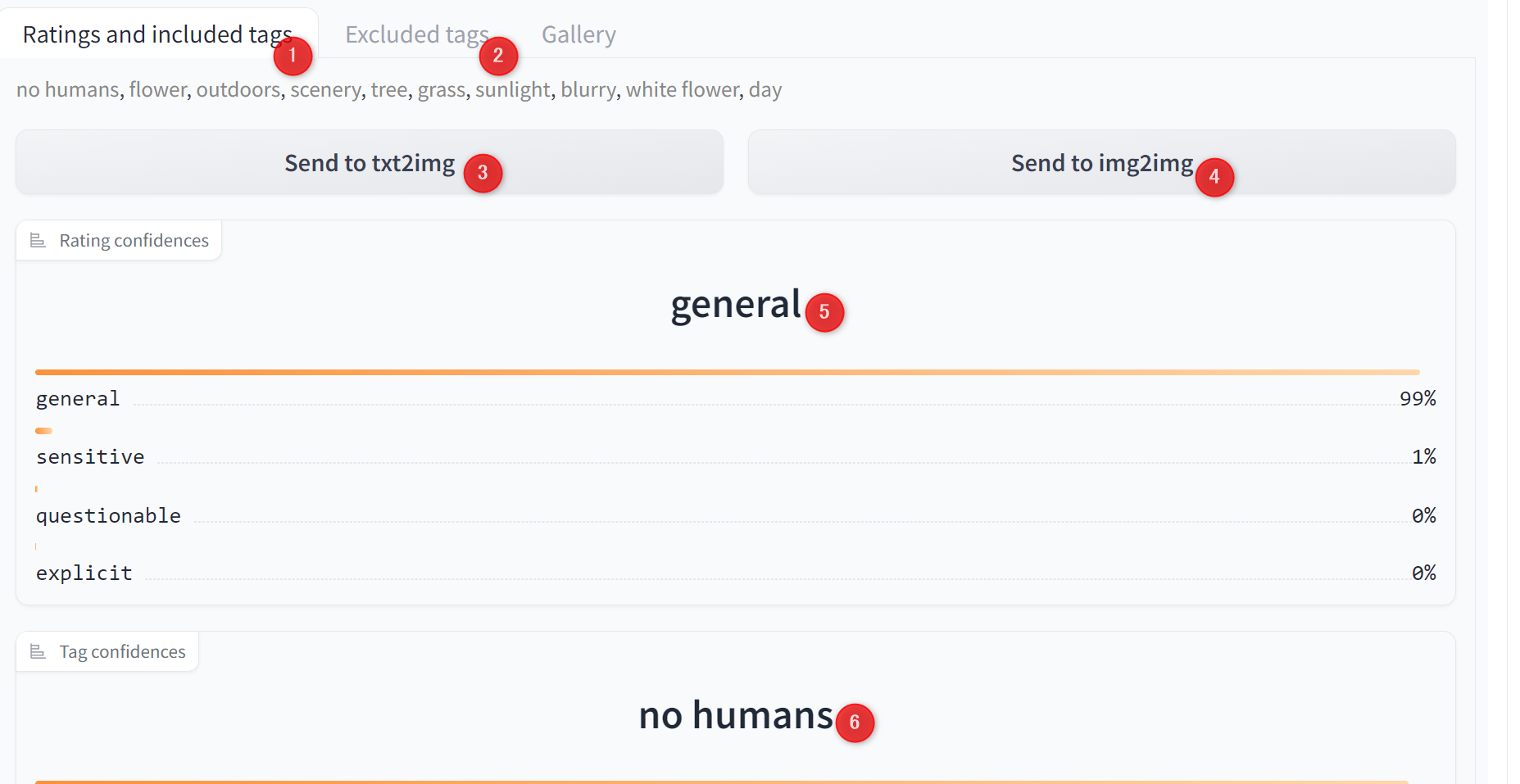
| ①Ratings and included tags | 抽出されたタグ一覧 |
| ②Excluded tags | 除外されたタグ一覧 |
| ③Send to txt2img | 抽出したタグをtxt2imgに送る |
| ④Send to img2img | 抽出したタグをimg2imgに送る |
| ⑤Rating confidences | 抽出されたタグが以下4つのどれに当てはまるか sensitive - センシティブ general - 一般的 questionable - 疑わしいタグ explicit - 明確 |
| ⑥Tag confidences | 抽出されたタグの割合 |
Interrogatorでモデルを変更すると、解析結果が変わります。いろいろ試してみてください。
複数の画像からキャプションデータを作る方法
今回はずんだもんの学習用データをお借りしました。
パスの指定
もし自分で用意した画像からキャプションデータを作りたい場合は、その画像を1つのフォルダにまとめておいてください。
今回はデータをお借りしたので、それをそのままC直下に置きました。
Batch from directoryタブを開いて、画像が入ったフォルダのパスを指定します。
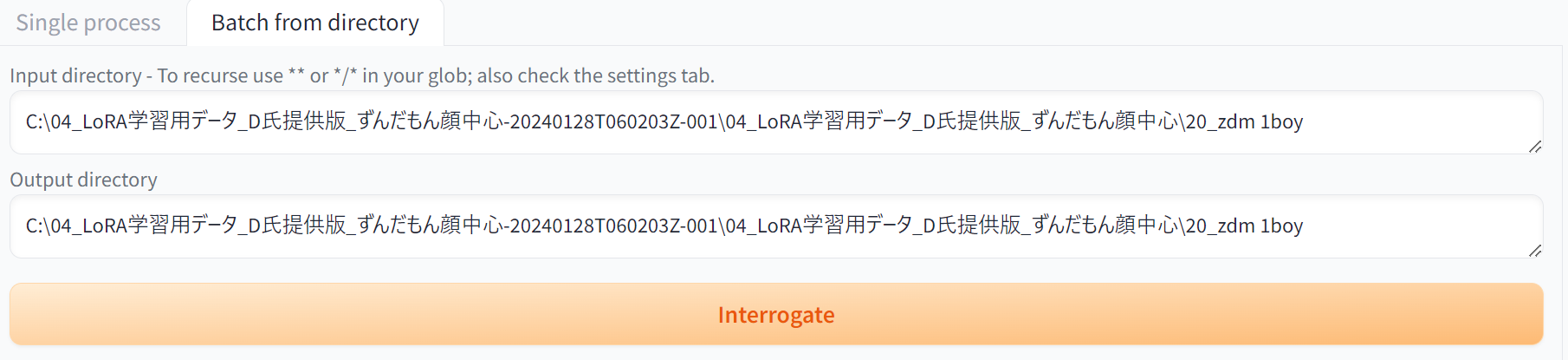
Input directoryは画像があるフォルダ、Output directoryはキャプションデータを出力フォルダです。
今回LoRA用なのでキャプションデータも同じフォルダに出力します。
トリガーワードを設定
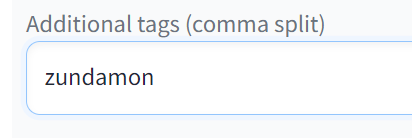
次にAdditional tags (comma split)にLoRAのトリガーワードを設定します。
トリガーワードは、キャプションデータの先頭に追加されるタグで、そのLoRAを使用するときに必要なものです。
一般的に服のLoRAなら服装の名称、特定のキャラクターならキャラクター名を入れます。
今回はzundamonと入力しました。
タグ抽出量の調整
Weight thresholdはしきい値を指定して、タグの抽出量を調整できます。
値が小さいほど抽出されるタグが多くなり、値が高いとタグは少なくなります。
主要なタグのみ抽出したいという場合は、値を上げると調整できます。
Min tag fraction in batch and interrogationsは、保持するタグの最低抽出率を指定できます。
デフォルトだと0.05なので、抽出されたタグの数が5%未満の場合、そのタグは除外されます。
値を上げると、抽出数が多いタグのみ保持されるという意味です。
基本はデフォルトでも問題ありません。

キャプションデータを作成
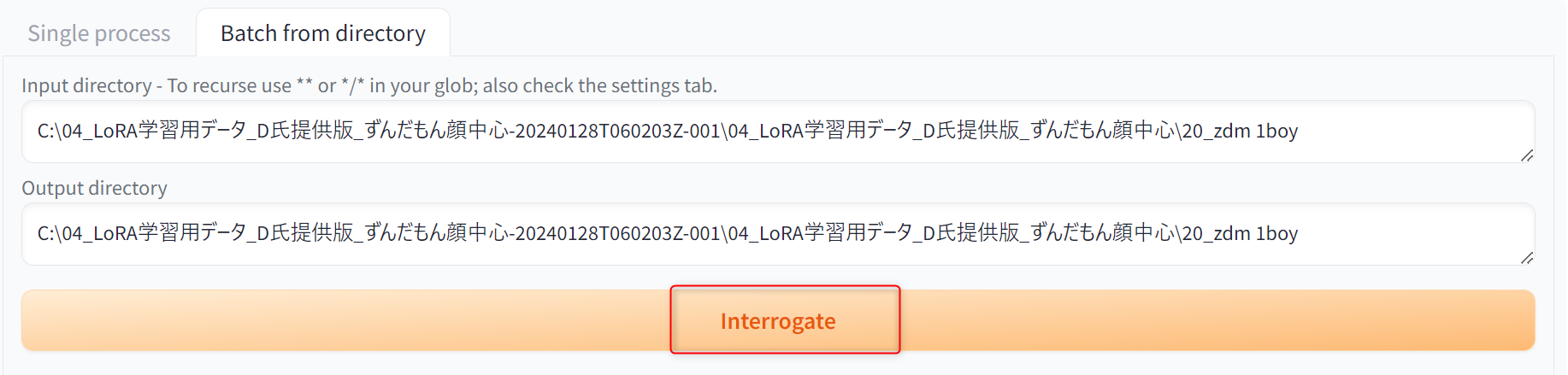
設定ができたらInterrogateをクリックすると、画像からキャプションデータを作成してくれます。

キャプションデータの調整
LoRA学習では、キャプションデータにないタグを強く学習します。
強く学習させたいタグを「Exclude tag」に入力して、再度Interrogateで上書きすると、キャプションデータからそのタグを削除することが可能です。
例えばgreen hairと入力して上書きすると、キャプションデータからgreen hairが削除されます。

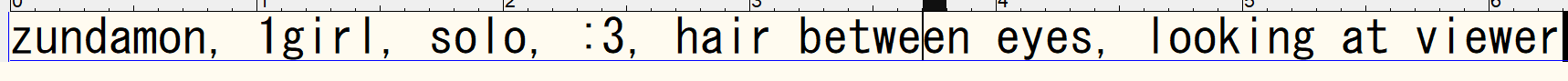
ただここの操作が少し不便で、タグをクリックすると自動で入力欄に追加できるのですが、Ratings and included tagsのタグは「Keep tag」、Excluded tagsのタグは「Exclude tag」に追加されます。
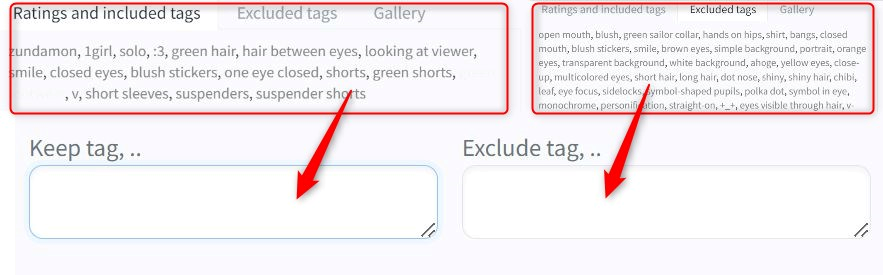
以下のボタンでまとめて追加することも可能。

ですので、一度学習させたい要素をkeep tagに追加し、コピペでExcluded tagsに貼り付ける必要があります。
「Ratings and included tags」のタグをそのままExcluded tags追加できた方が便利な気がするのですが、デフォルトだとこの仕様みたいです。
「tagger」の使い方まとめ
今回はStable Diffusion Web UI上でタグの解析&キャプションデータが作れる「tagger」を紹介しました。
taggerは画像からタグを抽出できる
複数の画像からキャプションデータも作れる
ただ操作が若干不便
Stable Diffusion Web UIの拡張機能でキャプションデータが作れるものだと、おそらくtaggerが一番簡単かと思います。
ただスタンドアローンで動かせるdataset-tag-editorというものもあるので、そっちが使えるならそっちの方が便利かもしれません。
結果としてできることは同じなので、興味がある方はぜひ使ってみてください。

