
LoRAはベースモデルとは別に学習したデータを適応できる技術です。
学習環境と学習ファイルを用意すれば簡単に自分で作成することができます。
今回は初心者の方でも比較的導入しやすい「kohya_ss GUI」というツールをご紹介します。
A1111の拡張機能でLoRAが作成できるツールも登場したので、こちらも参考にしてみてください。

kohya_ss GUIとは?
LoRAの学習・生成ができるsd-scriptsをGUIで使えるようにしたものです。
Kohyaさんという方がsd-scriptsを開発し、bmaltaisさんがkohya_ss GUIを作成してくれました。
https://github.com/kohya-ss/sd-scripts
https://github.com/bmaltais/kohya_ss
sd-scriptsはコマンドを書いて動かしますが、kohya_ss GUIはフォルダの指定やボタンだけ操作できるため、非常に簡単なLoRA作成ツールとなっています。
・sd-scriptsの使い方はこちら

kohya_ss GUIのインストールに必要なもの
kohya_ss GUIのインストールするために、pythonやgitなどが必要です。
- Python 3.10.11
- Git for Windows
- Visual Studio 2015, 2017, 2019, and 2022
Python 3.10.11のインストール
公式ページだと24年4月時点で、Python 3.10.11へのリンクが貼られています。
以前は3.10.6でも動かせましたが、アップデートにより3.10.11からじゃないと動かせないようです。
githubのページにリンクが貼られているのでこちらからダウンロードしてください。
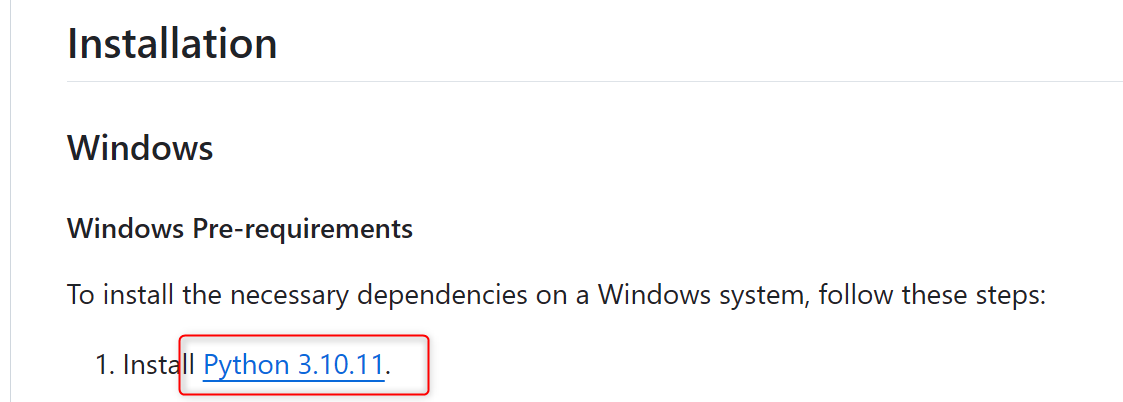
pythonを初めてインストールする方は、「Add python.exe to PATH」にチェックを入れてから「Install Now」をクリックします。
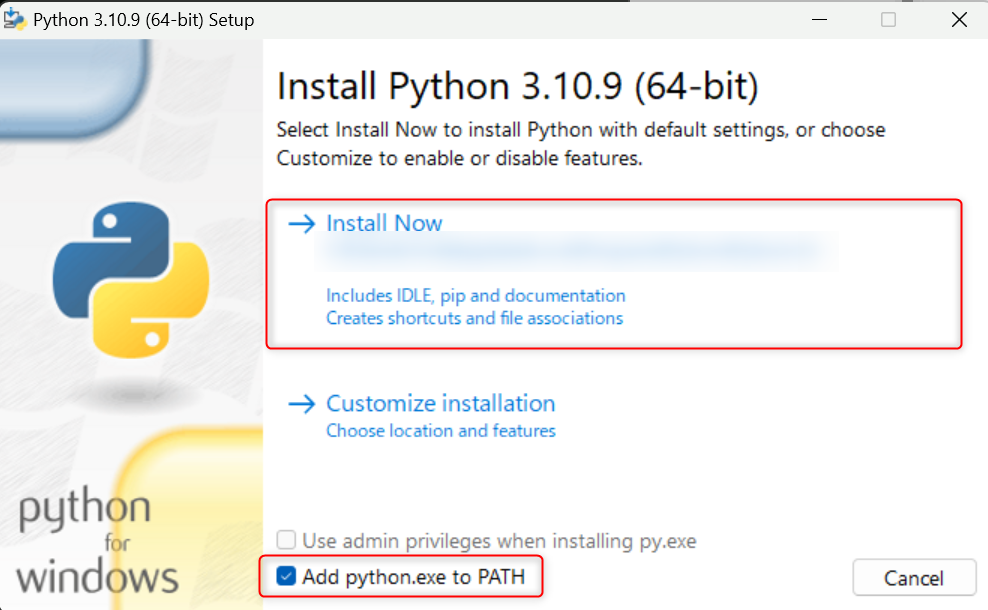
自動的にインストールが始まるので、終わったら画面を閉じてPythonのインストールは完了です。
既にpythonをインストール済みの方は、案内に従ってアップデートしてください。
なお、私の環境だと3.10.6から3.10.11にしても問題なくA1111は使用できています。
ただ何らかの不具合がある可能性もゼロではないので、バージョンアップは自己責任で行ってください。
Git for Windowsのインストール
Git for windowsはWindows環境でGitを使うためのソフトウェアです。
Gitで公開されているアプリケーションをインストールしたりするのに、Git for windowsが必要になります。
まず下記リンクに行き、ダウンロードをクリックします。

ダウンロードしたファイルを起動するとインストールが始まります。
項目は多いですが、全て「Next」で問題ありません。
最後の「View Release Notes」は更新履歴が確認できるものなので、チェックは外しても大丈夫です。
Finishをクリックすれば、Git for Windowsのインストールは完了です。
Visual Studio 2015, 2017, 2019, and 2022のインストール
Visual Studioはマイクロソフト社が開発・提供する統合開発環境です。
開発に必要なツールがパッケージされたもので、さまざまなツールがインストールできます。
以下のリンクから「https://aka.ms/vs/17/release/vc_redist.x64.exe」をクリックしてインストーラーをダウンロードします。
https://learn.microsoft.com/ja-jp/cpp/windows/latest-supported-vc-redist?view=msvc-170
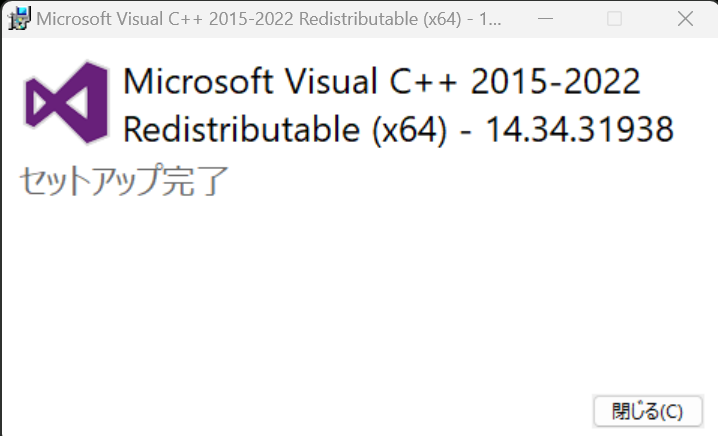
起動したら「ライセンス~」にチェックを入れてインストールをクリックします。
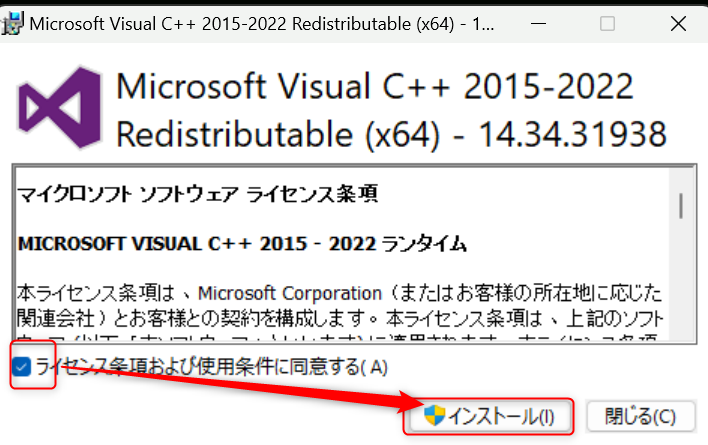
終わったら「閉じる」をクリックしてインストール完了です。
kohya_ss GUIのインストール
ターミナルを開いてインストールを実行
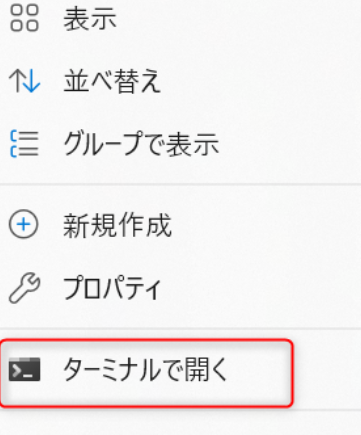
まず「kohya_ss GUI」をインストールしたいフォルダの空白部分で右クリックして、「ターミナルを開く」を選択します。
そのフォルダのパスでpowershellが起動するので、以下のコマンドを実行します。
git clone https://github.com/bmaltais/kohya_ss.gitそうすると「kohya_ss」フォルダが作成されるので、中にある「setup.bat」を起動してください。
これでセットアップメニューが表示されます。
セットアップメニューを順に実行
以下のメニューが表示されるので、順に実行していきます。
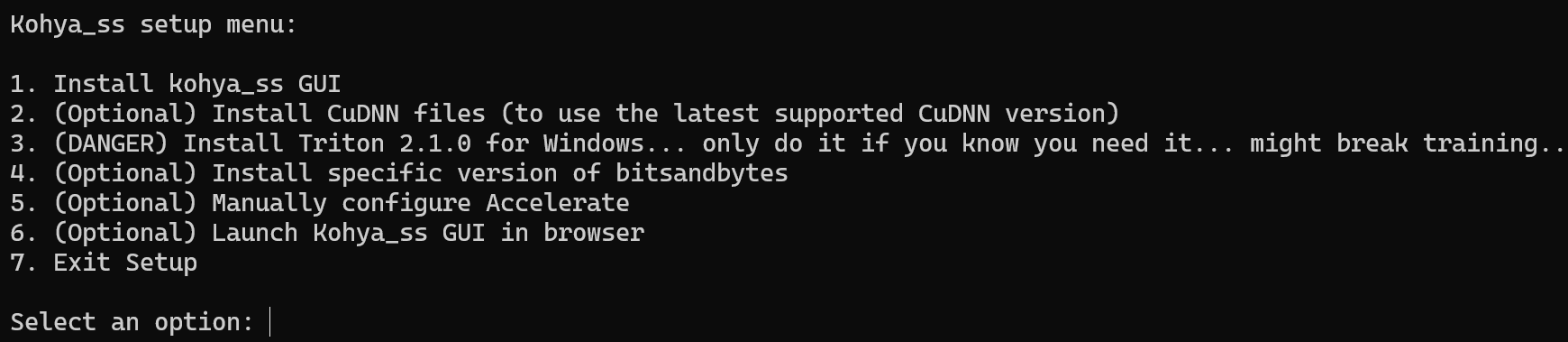
1.Install kohya_ss gui
Select an optionのところにカーソルがあるので、ここに数字を入力してメニューを実行します。
最初に「1」と入力してEnterを押してください。

kohya_ss guiに必要なものが自動的にインストールされるので、終わるまでしばらく待ちます。
再度セットアップメニューが表示されたらインストール完了です。
2.(Optional) Install cudann files (avoid unless you really need it)
2はNVIDIA 30X0/40X0 GPUを使用している方の学習速度を、向上させるファイルをインストールできます。
なお、こちらはpytorch1系で効果があるものらしく、現在はpytorch2のため必要ないそうです。
インストールしてもしなくても問題なく動くので、どちらでも構いません。
インストールする場合は「2」と入力してEnterを押します。
次の「3」は必要だと分かっている場合のみインストールしてくださいと書かれているので、今回は飛ばします。
4.(Optional) Install specific version of bitsandbytes
これはbitsandbytesというビット操作やバイト操作を簡素化するモジュールです。
「4」と入力してEnterを押すと、インストールするbitsandbytesのバージョンを指定できます。
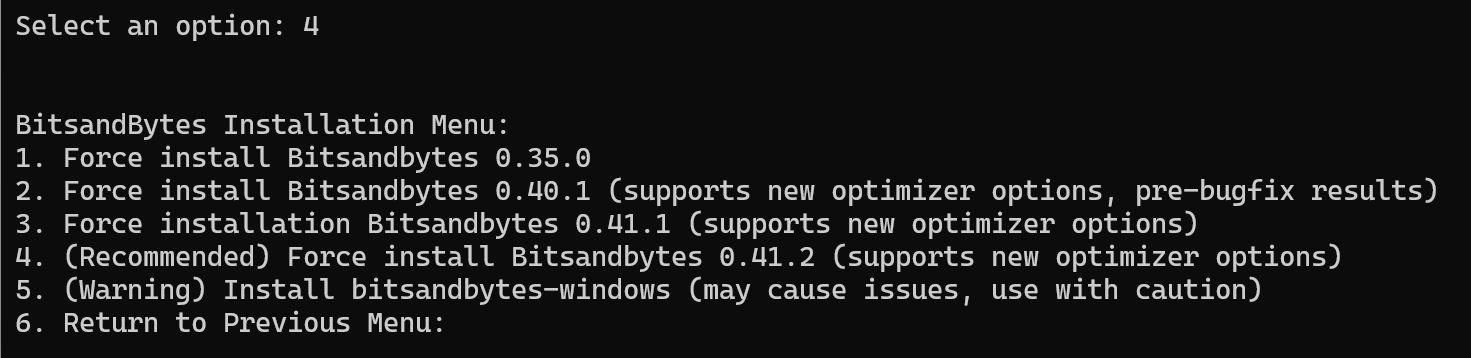
環境によって推奨バージョンは異なるようですが、今回はRecommendedと書いてある4をインストールします。
再度4と入力してEnterを押せば、インストールが始まります。
5.(Optional) Manually configure Accelerate
これはAccelerateというライブラリの設定をするものです。
いくつか質問されるので、それに回答していきます。
公式に回答例があるので、その通りに入力すれば問題ありません。

- This machine
- No distributed training
- NO
- NO
- NO
- all
- fp16 or bf16
「*」が付いてる方が選択されている回答で、「NO」と「all」はキーボードで入力する必要があります。
7の質問は、こちらの動画だとRTX30,40系でVRAM12GBの場合、bf16の方がいいそうです。
fp16はキーボードの「1」、bf16はキーボード「2」で選択できます。
これでInstall kohya_ss guiは完了です。
6.(Optional) Launch Kohya_ss GUI in browser
最後に「6」を入力してEnterを押すとGUIを起動できます。
このようにWeb UIが表示できていれば「kohya_ss GUI」の導入は完了です。
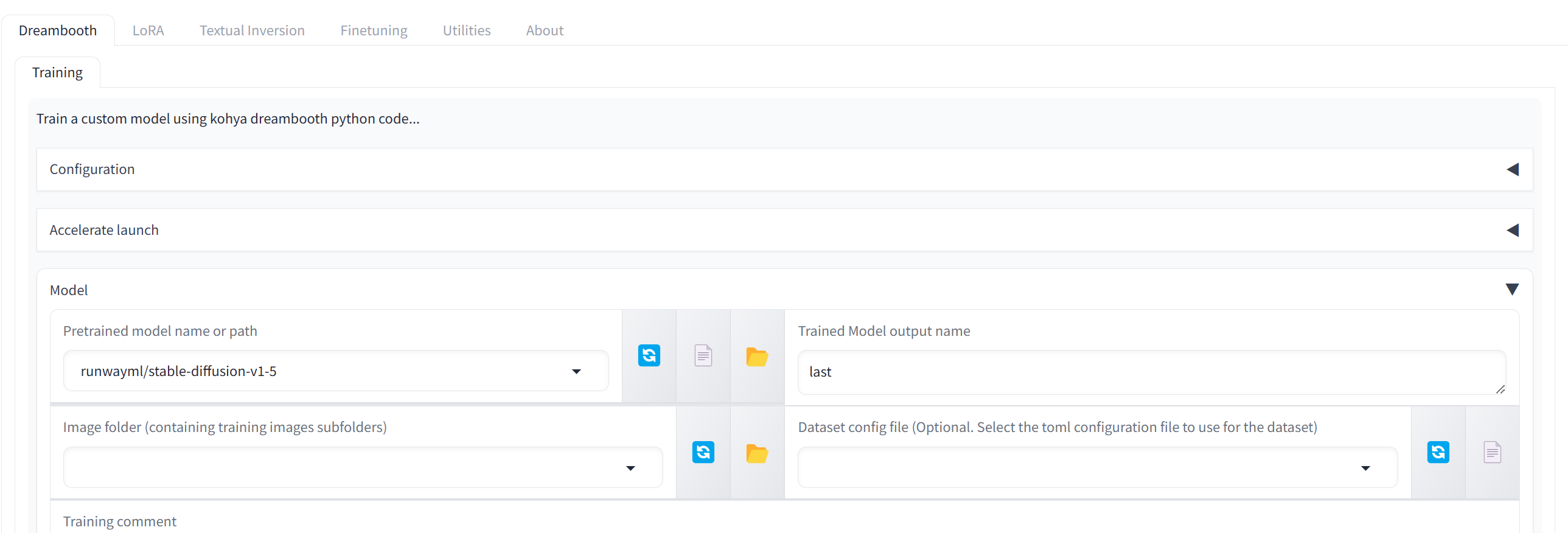
2回目は以降も再度setup.batを起動して、6を実行すれば起動できます。
また「kohya_ss」内にある「gui.bat」を実行して、記載されたURLをCtrl+左クリックで開けば、こちらでもWeb UIを開けます。

アップデートする方法
もし何らかの変更がありアップデートする場合は、kohya_ssのパスでターミナルを開き、以下のコマンドを実行でアップデートできます。
git pullなお、結構頻繁にUIなどが変更されており、アップデートしたら動かないといった現象も少なくありません。
githubページでアップデート内容が確認できるので、そちらを見てからアップデートするのをおすすめします。
kohya_ss GUIを使う前の準備
学習に使用する画像やキャプションデータを用意します。
学習用の画像を用意
まず学習させたい画像を特定のフォルダにまとめておきます。
今回東北ずん子のデータをお借りしました。
AI画像モデル用学習データのところにあるリンクからGoogleドライブに飛び、「01_LoRA学習用データ」→「zunko」を右クリックしてダウンロードできます。
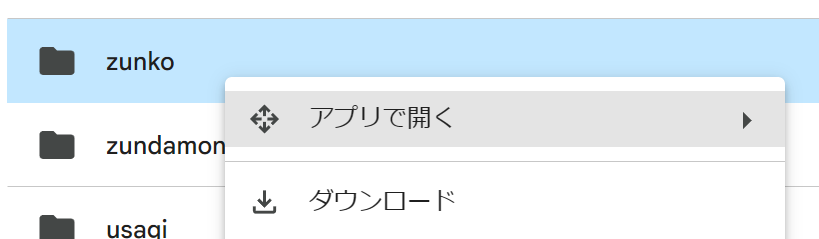
https://zunko.jp/con_illust.html
学習用データを保管するフォルダを作成し、その中に画像を入れておきます。
今回はkohya_ssフォルダ内にtrainというフォルダを作り、その中にzunkoのフォルダを移動させました。
- kohya_ss
- train
- zunko
- train
なお、フォルダ名やフォルダのパスは任意の場所でも大丈夫です。
ただパスに関してはエラーになってしまう可能性があるため、ドライブ直下など日本語が含まれない場所をおすすめします。
フォルダ名の設定
「zunko」のフォルダ名を「100_zunko」に変更します。
これは左から「画像1枚の学習回数、トリガーワード」を指定したものです。
学習回数についてはさまざまな意見があるため、結果を見て調整してみてください。
なお、GUI側で上限を指定できるので、ここが多くなってしまっても調整はできます。
トリガーワードはLoRAを使用するときに使うキーワードです。
LoRAと一緒に使用することで再現率が高くなります。
キャプションデータの作成
キャプションデータは画像の情報をテキストで抽出したものです。
zunkoのフォルダには既に作られていますが、自分で用意した画像の場合は、キャプションデータも作る必要があります。
Kohya_ss GUIでも作れますが、一番簡単なのはdataset-tag-editorを使う方法です。
A1111の拡張機能、またはスタンドアローンとしても使うことができます。
別途解説記事を書いているので、こちらを参考にしてみてください。

khoya_SS GUIの使い方
学習データが準備できたら、Kohya_ss GUIの設定をしていきます。
細かい設定がいろいろできますが、とりあえず動かすのに必要な部分のみご紹介します。
GUIを開いたらまずLoRAタブに移動してください。

Modelの設定
Modelの項目で、学習元となるモデルなどを指定します。
「Pretrained model name or path」に元となるモデルデータを指定してください。
今回はStable Diffusionでよく使用しているAnyLoRAを指定しました。
モデルのパスコピペ、または右側真ん中のアイコンから選択できます。

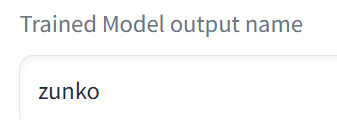
「Trained Model output name」では、出力するLoRAの名前を決められます。今回は「zunko」にしました。
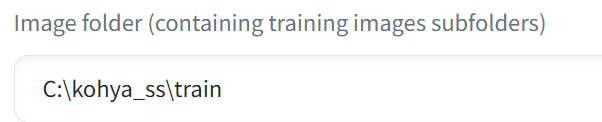
「Image folder」では、学習データがあるフォルダのパスを指定します。zunkoではなく上の階層のtrainであることに注意してください。
Foldersの設定
Foldersでは出力先を指定します。
「Output directory for trained model」にLoRAを保存したいパスを指定してください。
LoRAをすぐ使いたい方は、Stable DiffusionのLoRAフォルダを指定するのが無難です。

Parametersの設定
ここはデフォルトでも問題ありませんが、学習回数などを調整できます。
Epochは、全体の学習を何回繰り返すかを指定できます。
Max train stepsは総学習回数の上限を指定できます。デフォルトでは1600となっています。
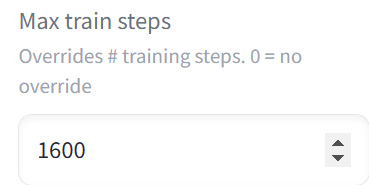
ちなみに「画像枚数×1枚の学習回数×エポック数=総ステップ数」です。
今までの設定だと「画像枚数61×1枚の学習回数100×エポック数1=6100」になりますが、上限が1600なのでそれ以上学習されることはありません。
学習開始
上記の設定ができたら一番下の「Start training」をクリックすると学習が始まります。

学習が終わると指定したパスにLoRAが出力されるので、それを使用して画像生成が可能です。
今回作ったLoRAで生成したらこんな感じでした。
1girl, <lora:zunko:1>, zunko
weight1だとちょっと元画像の影響が強いので、Weight下げてヘアバンドと着物入れたら、良い感じに馴染みました。
1girl, <lora:zunko:0.7>, zunko, hair band, kimono
キャラクターの特徴がでない場合は、それをプロンプトで追加してみてください。
「kohya_ss GUI」のインストールとLoRA学習方法まとめ
今回は「kohya_ss GUI」のインストールとLoRA学習方法について解説しました。
ほぼデフォルトのまま作りましたが、そこまでクオリティは悪くないと思います。
そこまで難しい設定や操作もないので、ぜひ挑戦してみてください。
