
2024年2月5日にStable Diffusion Web UI forgeがリリースされました。
こちらはStable Diffusion Web UIと同じ外観で、SDXLの高速化やデフォルトでさまざまな機能が搭載されたものです。
今回はこのStable Diffusion Web UI forgeについて、ご紹介します。
Stable Diffusion Web UI forgeとは?
forgeは、Stable Diffusion Web UIを改良したような新しいUIです。
ControlNetやFooocusを開発したlllyasvielさんがリリースしたもので、外観はほぼWeb UIのまま、SDXLの高速化やさまざまな機能が追加されています。
まず画像生成について、SDXL・1024サイズの画像生成を通常のStable Diffusion Web UIと比べた場合、8GB VRAMで約30~45%、6GB VRAMで約60~75%、24GB VRAMで約3~6%高速化が期待できるとのこと。
またコマンドライン引数は自動で最適化してくれるので、特に設定はいらないそうです。
デフォルトでFreeUやKohya HRFixなど画像クオリティを上げる機能や、AI動画が作れるSVD、3D画像が作れるZ123なども搭載されています。
lllyasviel/stable-diffusion-webui-forge
Stable Diffusion Web UIと混同してしまいそうなので、この記事では「forge」で統一します。
forgeのインストール
既にgitを導入している方であれば、git cloneでインストールできます。
インストールしたいパスでターミナルを開き、以下のコマンドを実行してください。
git clone https://github.com/lllyasviel/stable-diffusion-webui-forge.git「stable-diffusion-webui-forge」というフォルダが作成されるので、中の「webui-user.bat」を起動すれば、必要なものがインストールされて自動でforgeが開きます。
また下記URLの「Click Here to Download One-Click Package」から7zをダウンロードしてインストールもできます。
現在頻繁にアップデートが行われているようなので、中のupdate.batを実行してからrun.batを実行してください。
そうすると必要なものがインストールされ自動でforgeが開きます。
2つの違いはアップデートを自分でやるか、バッチファイルでやるかくらいです。
gitでインストールした場合は、git pullコマンドを使って自分で更新する必要があります。
forgeの使い方
基本的な使い方はStable Diffusion Web UIと同じです。
txt2imgでプロンプト入力して画像生成したり、好きな拡張機能をインストールしたりできます。
ここではStable Diffusion Web UIと違う部分のみご紹介します。
Stable Diffusion Web UIの使い方は以下の記事を参考にしてみてください。


モデルを取り込む方法
モデルの取り込み方は主に3つです。
- webui-user.batでパスを指定
- シンボリックリンクを作成
- モデルを直接入れる
webui-user.batでパスを指定
既にStable Diffusion Web UIをインストールしている場合は、forgeのwebui-user.batをテキストファイルなどで開き、モデルがあるパスを指定すれば使用できます。
行頭の@REMはコメント用なので、有効にしたい行の@REMは削除してください。
・C直下にstable-diffusion-webuiがある場合
変更前:@REM set A1111_HOME=Your A1111 checkout dir
変更後:set A1111_HOME=C:/stable-diffusion-webuiまたWindowsのパスをそのままコピペすると区切り記号が「\」になっているので「/(バックスラッシュ)」に直す必要があります。
VAEのパスを指定する場合は、以下の行を追加すれば読み込めます。
--embeddings-dir %A1111_HOME%/embeddings^
--vae-dir %A1111_HOME%/models/VAE^←これ
--lora-dir %A1111_HOME%/models/Lora@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
@REM Uncomment following code to reference an existing A1111 checkout.
set A1111_HOME=C:/stable-diffusion-webui
set VENV_DIR=%A1111_HOME%/venv
set COMMANDLINE_ARGS=%COMMANDLINE_ARGS% ^
--ckpt-dir %A1111_HOME%/models/Stable-diffusion ^
--hypernetwork-dir %A1111_HOME%/models/hypernetworks ^
--embeddings-dir %A1111_HOME%/embeddings ^
--vae-dir %A1111_HOME%/models/VAE ^
--lora-dir %A1111_HOME%/models/Lora
call webui.bat
xformersも使用可能ですが、一度使用してからオフにするとうまく起動できないようです。
もし起動できない場合は、site-packages内にあるxformersのフォルダを削除すると起動できます。
なお、forgeはxformersを使用すると処理が遅くなってしまうようなので、使用しない方がいいかもしれません。
シンボリックリンクで読み込む方法
モデルがあるフォルダのシンボリックリンクを作成すれば読み込めるようになります。
checkpointのシンボリックリンクを作る場合は、コマンドプロンプトを「管理者として実行」で開いて以下のコマンドを実行します。
mklink /D "シンボリックリンクを作成するパス" "モデルがあるパス"同名のフォルダがある場合はシンボリックリンクを作成できないので、事前に削除、または新しいフォルダで作成してください。
例えばA1111というフォルダのシンボリックリンクを作って、モデルを読み込む場合は以下のようにします。
・両方C直下にある場合
mklink /D "C:\stable-diffusion-webui-forge\models\Stable-diffusion\A1111" "C:\stable-diffusion-webui\models\Stable-diffusion"そうするとショートカットアイコンでフォルダが作成され、既存のパスからモデルを読み込めるようになります。


モデルを直接入れる
もしforgeが最初のUIの場合は、それぞれ対応しているフォルダにモデルデータを直接入れてください。
対応しているパスは以下の通りです。
embeddings - stable-diffusion-webui-forge\embeddings
hypernetworks - stable-diffusion-webui-forge\models\hypernetworks
checkpoint - stable-diffusion-webui-forge\models\Stable-diffusion
LoRA - stable-diffusion-webui-forge\models\Lora
VAE - stable-diffusion-webui-forge\models\VAE
forgeに追加されている機能
txt2imgには画像のクオリティを上げるもの、他にもAI動画や3D画像生成機能が追加されいます。
細かい調整方法はわからない部分も多かったので、とりあえず簡単な機能説明と比較画像のみご紹介します。
ControlNet
forgeにはデフォルトでControlNetが搭載されています。
ControlNetは、画像から情報を抽出して新たに画像生成ができる機能です。
モデルは自分で用意する必要があります。
既に別のUIで使用している場合はシンボリックリンク、まだの方は直接導入してください。
モデルは以下のパスに入れれば反映されます。
stable-diffusion-webui-forge\models\ControlNet使い方は同じなのでこちらの記事を参考にしてみてください。

FreeU
FreeUは画像の品質を向上させる拡張機能です。
デフォルトの設定だと大きな変化はありませんが、リボンや花の色などが少し変化しています。

ChenyangSi/FreeU: FreeU: Free Lunch in Diffusion U-Net
HyperTile
HyperTileは画像生成速度が短縮できる機能です。
通常時の生成で22.1 sec.、HyperTile使用時は14.3 secでした。
生成時間は短縮されていますが、デフォルトの設定だと画像がちょっと崩れてしまうので、パラーメータで調整が必要です。
・右がHyperTile

Kohya HRFix
hires.fixを使わなくても画像を綺麗に出力できる機能のようです。
hires.fixなしで生成したところ、結果は変わってしまいますが、比較的綺麗な画像が生成できました。

SelfAttentionGuidance
こちらは画像の品質を上げる機能のようです。
デフォルトだとそこまで変化はありませんが、線が少しくっきりしたような印象があります。

StyleAlign
StyleAlignは他の拡張機能を連携できる機能のようですが、具体的な使い方がわかりませんでした。
以下のページではDynamic Promptsと一緒に使って解説しています。
SVD(Stable Video Diffusion)
SVDは画像から動画が作成できる機能です。
別途モデルが必要なので、以下のリンクから「svd.safetensors」をダウンロードしてください。
stabilityai/stable-video-diffusion-img2vid at main
モデルは以下のパスに置きます。
stable-diffusion-webui-forge\models\svdSVDタブで画像を取り込んで、モデルを選択します。
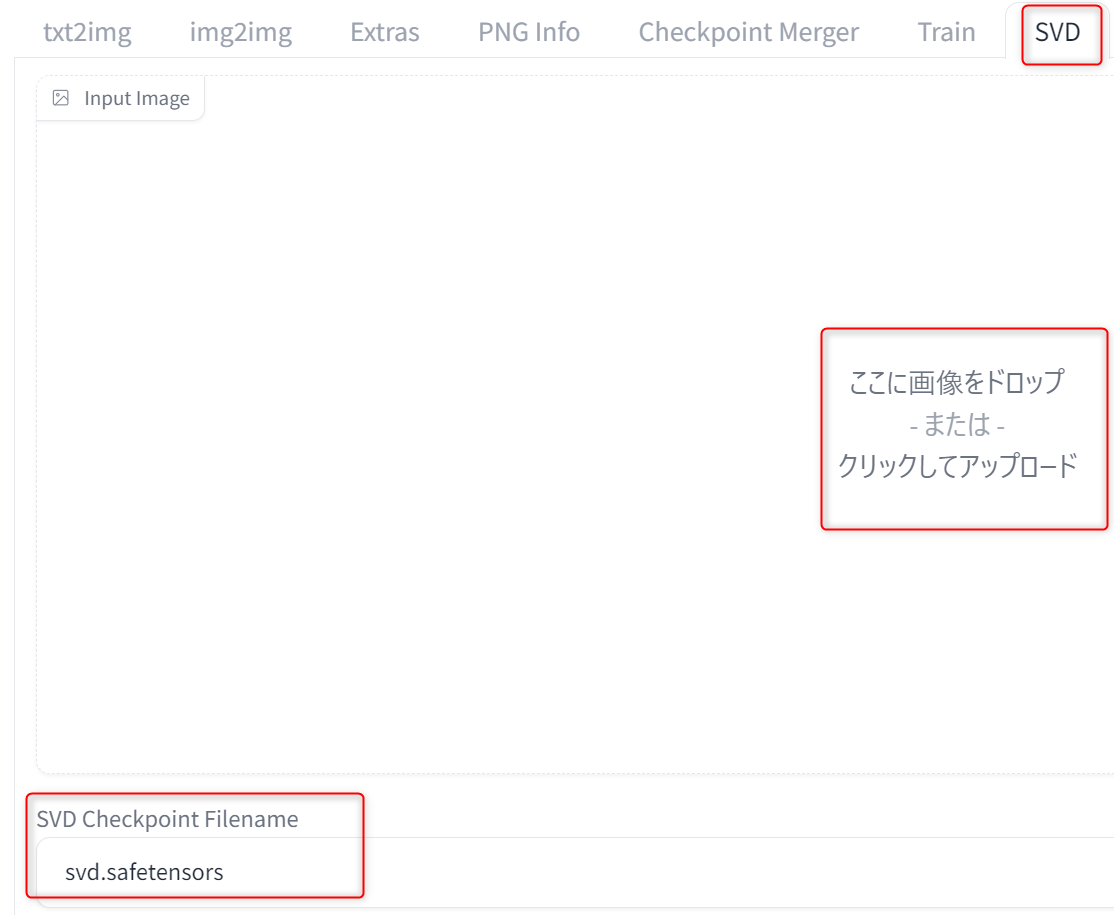
なお、生成した画像は、ビデオアイコンを押すとSVDタブに送ることができ、自動で画像サイズも合わせてくれます。

手動で取り込んだ場合は、画像サイズだけ合わせてください。
パラメータをデフォルトのまま生成すると、以下のような動画が作れます。
なお、元画像によって結構クオリティが変わるみたいです。
パラーメータはそれぞれ以下の通りです。
| Video Frames | 動画の長さ |
| Motion Bucket Id | 含まれる動きの量 |
| Fps | 1秒間に使用する画像枚数 |
| Augmentation Level | 追加されるノイズの量 値が大きいと動きが増加するが、元画像の変化も多くなる |
| Sampling Steps | 動画生成を何ステップで行うか |
| CFG Scale | 最後のCFG |
| Sampling Denoise | ノイズ除去強度 |
| Guidance Min Cfg | 最初のCFG |
| Sampler Name | 使用するサンプラー |
| Scheduler | 使用するスケジューラー |
| Seed | シード値(変更すると動画も少し変化します) |
CFGに関してはちょっとよくわからず、ComfyUIのページやRedditでMotion Bucket Id、Augmentation Levelについて比較・解説している方がいるので、こちらも参考にしてみてください。
Stable VIde Diffusion motion bucket id comparison : r/StableDiffusion
Z123
Z123は元の画像から3D画像が生成できる機能です。
Z123を使用するには背景を透過させた画像と専用のモデルが必要です。
まず何らかの画像を生成して背景を透過させてください。
今回は公式に書いてある通り、「A simple 3D render of a friendly dog」で生成して、clipdropで背景を切り抜きました。
clipdropはgoogleアカウントなどでログインすれば使用できます。
https://clipdrop.co/remove-background
・作った画像

次に以下のリンクからモデルをダウンロードします。
「stable_zero123.ckpt」か「stable_zero123_c.ckpt」をダウンロードしてください。
stabilityai/stable-zero123 at main
モデルは以下のパスに移動させます。
stable-diffusion-webui-forge\models\z123あとはforgeのZ123タブで画像を取り込み、モデルを「stable_zero123.ckpt」にします。
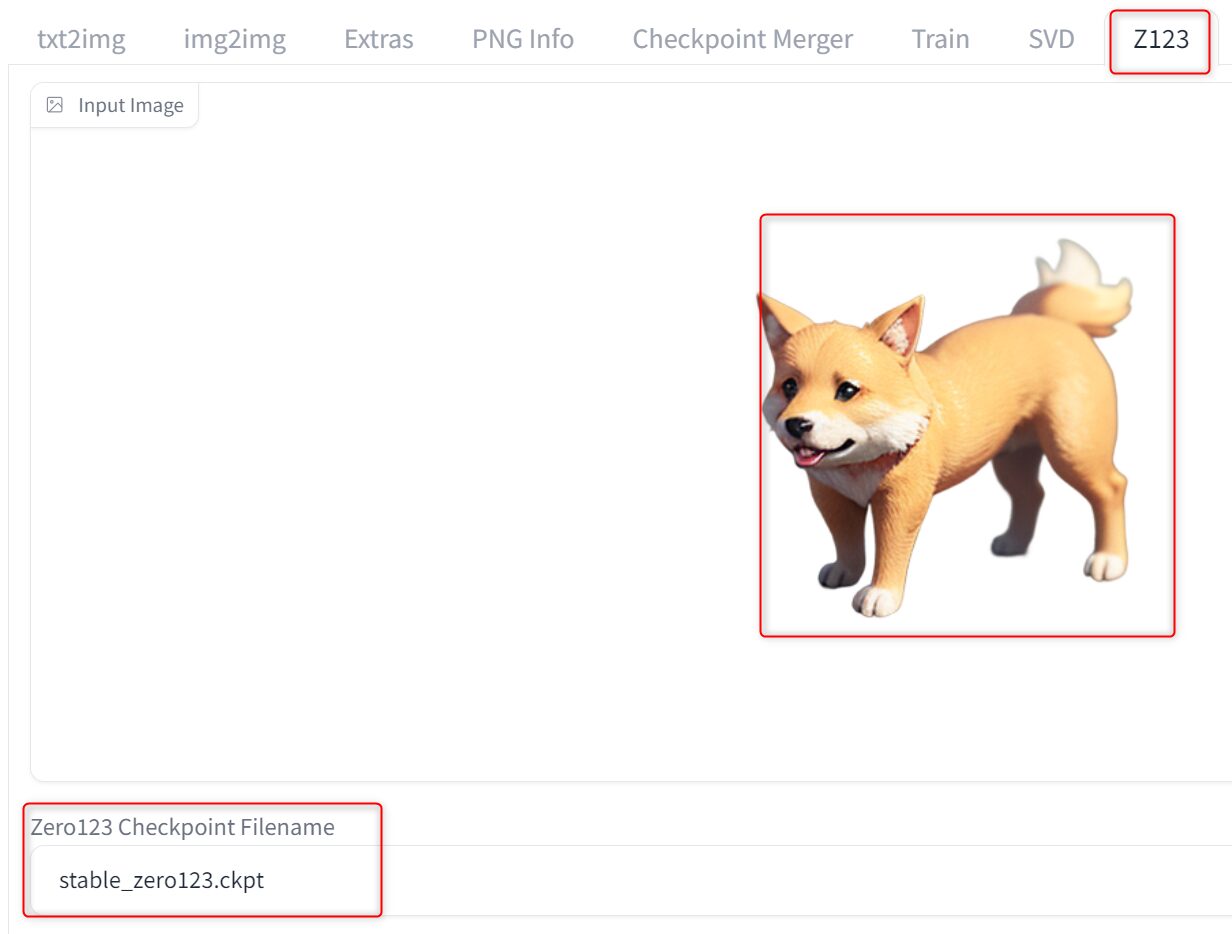
これで生成するといろんな方向から撮影したような画像が生成されるはずなんですが、設定のせいか後ろからの画像しか生成できませんでした。

本来はこういう画像ができるはずです。

引用:stabilityai/stable-zero123 · Hugging Face
こちらはもう少し使ってみて、パラーメータの設定など詳細がわかったら追記します。
forgeのSDXL画像生成速度は?
dreamshaperXL10で以下の画像を生成したところ、Stable Diffusion Web UIで48.6 sec、forgeで 21.7 secでした。約55%ほど高速化できています。
Stable Diffusion Web UI - 48.6 sec
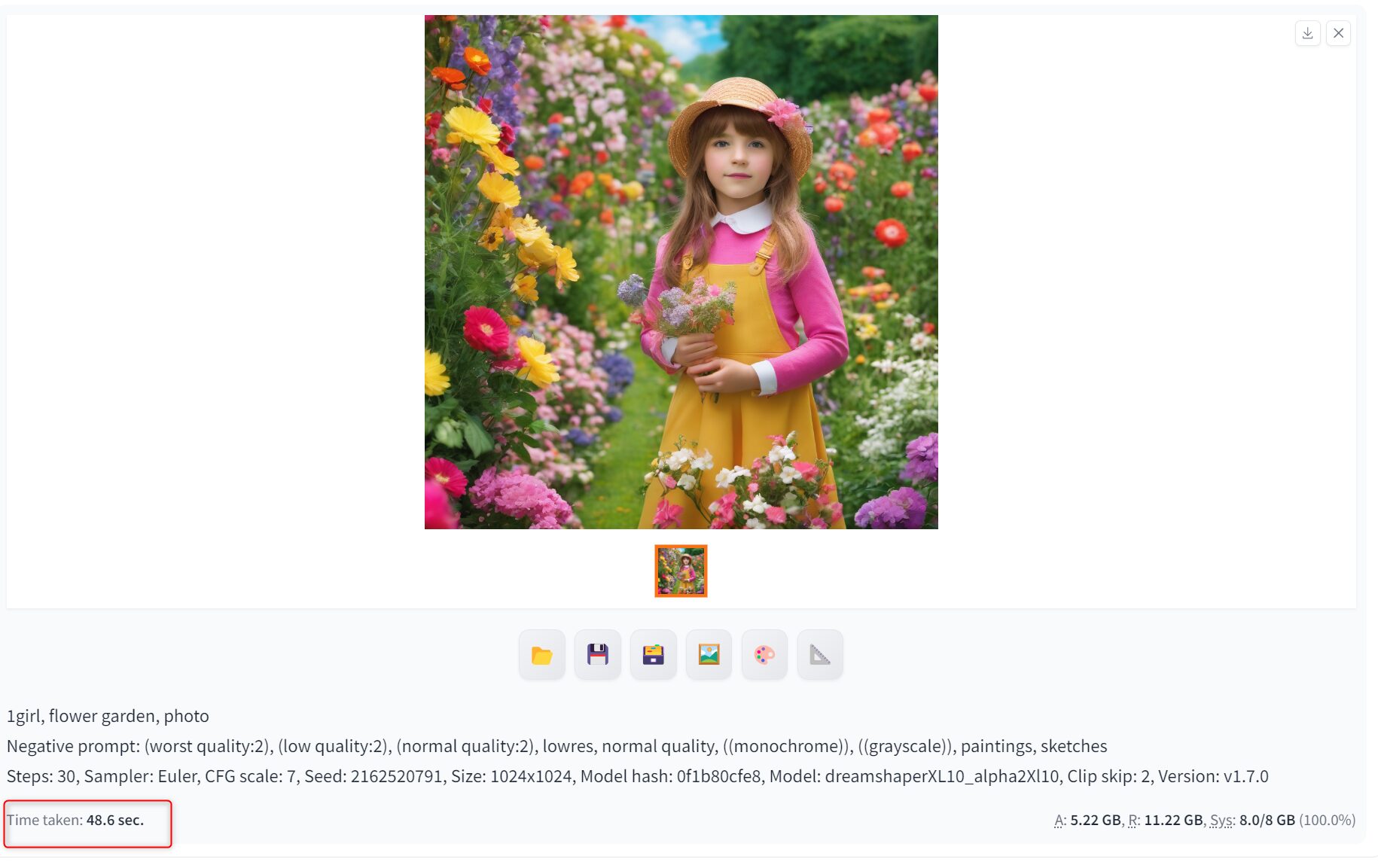
forge - 21.7 sec

VRAMの消費も抑えられているので、私のようにVRAM8GBの方でSDXLを使いたい方はforgeの方がいいかもしれません。
ただ1枚しか検証していないので、複数枚生成やコマンドライン引数などで多少前後すると思われます。
forgeの使い方まとめ
今回はStable Diffusion Web UI forgeの使い方をご紹介しました。
- forgeはSDXLの生成が速い
- デフォルトでControlNetや画像クオリティを上げる機能が搭載
- SVDが使える
- Z123も使える
- 使用感はほぼStable Diffusion Web UIと一緒
SDXLについてはFooocusも高速化されていたのですが、SDXL専用のため、SD1.5の画像生成はできませんでした。
それを考えるとforgeはどちらも生成できるので、利便性は高いかもしれません。
またStable Diffusion Web UIと外観が同じなので、乗り換えもそこまで苦じゃないと思います。
SVDやZ123も使い方次第でいろいろ遊べると思うので、興味がある方はぜひ使ってみてください。
