
画像生成をしていて「この画像と同じポーズを取らせたい」「表情の一部だけ修正したい」と思ったことはないでしょうか?
こういった悩みを解決してくれるのが「ControlNet 1.1」という拡張機能です。
既存の画像からポーズや線画などの情報を抽出して、それを元に新しい画像を生成できます。
今回はこの「ControlNet 1.1」の使い方について、詳しく解説します。
機能が多く長くなってしまったので、読みたい部分から読んでいただければ幸いです。
- ControlNetでどんなことができるのか知りたい
- 画像の一部を修正したい
- 既存の画像を再構成して新しい画像を生成したい
まずはStable Diffusion Web UIのインストール
ControlNet 1.1はStable Diffusion Web UIで動かせる拡張機能です。
そのため、事前にStable Diffusion Web UIをインストールしておく必要があります。
インストールがまだの方はこちらの記事を参考にしてみてください。

ControlNetって何ができるの?
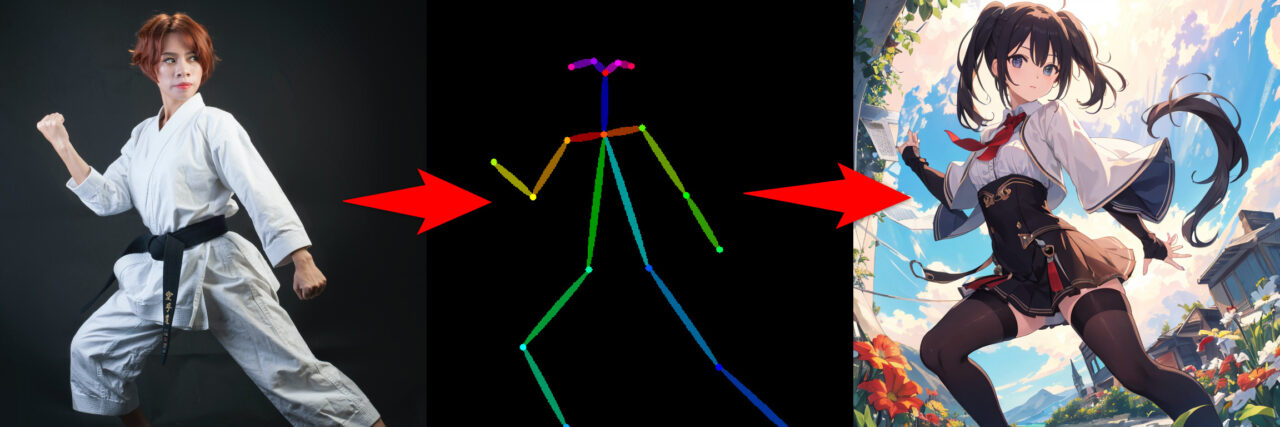
ControlNetは既存の画像からさまざまな情報を抽出して、そこから新しい画像を生成できる機能です。
例えば以下の画像からopenposeというプリプロセッサで、ポーズ推定をします。
ポーズ推定は人物の画像から身体の配置を解析し、動きや姿勢を推定する技術です。

ポーズ推定結果が取得できると、それを元にした新しい画像が生成できます。
他にもinpaintという機能を使うと、画像の補間・修正が可能です。
「1girl,summer,smile」というプロンプトで生成した画像を読み込み、修正したい部分にマスクをかけます。

inpaintというプリプロセッサを使って、「crying」と入力すると、マスクをかけた部分にそのプロンプトが反映されます。

このように画像から抽出した情報で、新しい画像を生成できるのがControlNetです。
Stable Diffusion Web UIにControlNetをインストールする方法
ControlNetはURLから直接インストールできます。
まずStable Diffusion Web UIを起動して「Extensions」→「Install from URL」タブを開き、下記URLを入力して「Install」をクリックします。
https://github.com/Mikubill/sd-webui-controlnet.git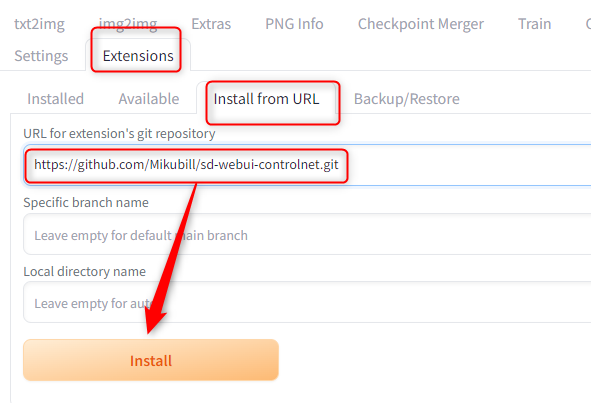
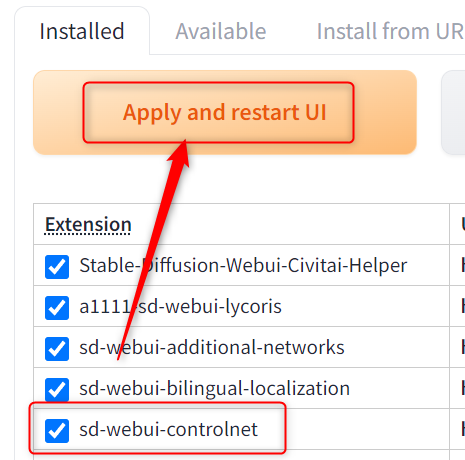
これで「installed」タブに「sd-webui-controlnet」が追加されていれば、無事インストールできています。
「Apply and restart UI」をクリックしてリスタートしてください。
ControlNetのモデルをダウンロードする方法
ControlNetを使うために、別途モデルをダウンロードする必要があります。
モデルはHugging Faceからダウンロードできます。
下記ページに飛ぶとLFSというアイコンがついているファイルがあるので、そこから使用したいモデルをダウンロードします。
予め機能がわかっている方は、使いたいモデルだけでも問題ありません。


ダウンロードしたファイルは、以下のパスに移動させます。
stable-diffusion-webui\models\ControlNetこれで準備は完了です。
モデルをまとめてダウンロードする方法
もし全モデルを使用したい、1つ1つダウンロードするのが面倒という方は、cloneコマンドでまとめてダウンロードすることも可能です。
まず「stable-diffusion-webui\models\ControlNet」に移動して、空白部分で右クリック→ターミナルを開きます。
ターミナルに以下のコードをコピペして実行します。
git lfs install
git clone https://huggingface.co/lllyasviel/ControlNet-v1-1これでControlNetの全てのファイルがローカルにクローンされます。
容量が大きいので少しかかりますが、ターミナルに以下の表示が出たらダウンロードは完了です。

なお、この方法だとモデル以外のファイルも全てダウンロードされるため、「.pth」という拡張子以外は削除してください。
また、ファイルが「ControlNet-v1-1」というフォルダの中に入るので、モデルデータはControlNetの直下に移動させる必要があります。
ControlNetの基本的な使い方
最初にControlNetの基本的な使い方について解説します。
ControlNetはプリプロセッサで元画像から情報を抽出し、それに対応するモデルで画像を出力します。
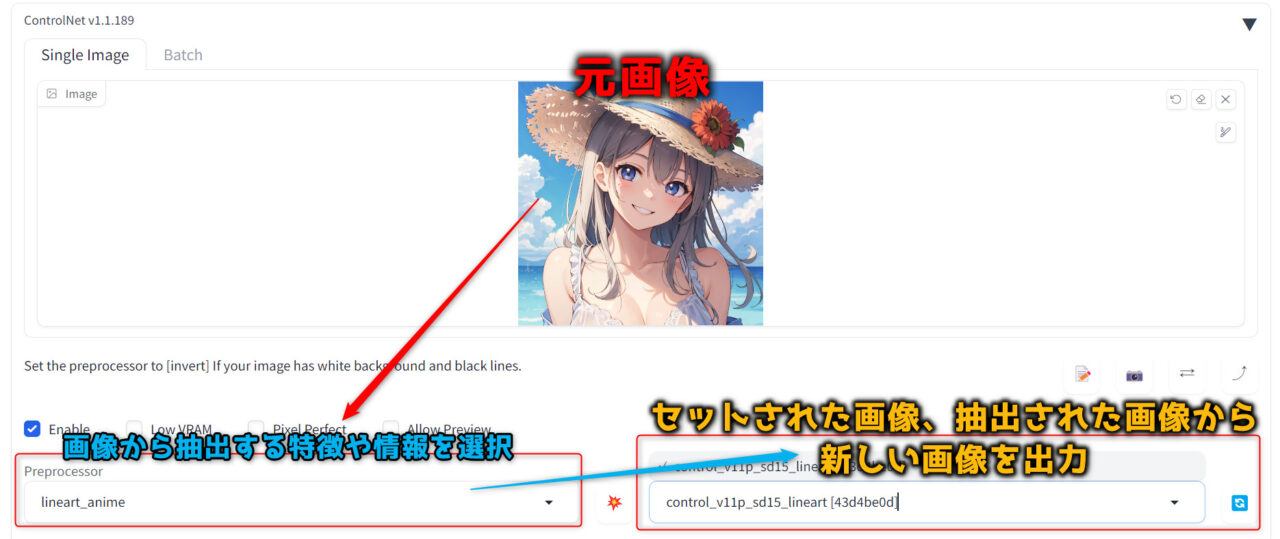
プリプロセッサは「セットした画像から何の情報を抽出するか」を選べるものです。
例えばセットした画像からポーズを抽出したい場合は「openpose」、線画を抽出したいなら「lineart」を使用します。
使用するプリプロセッサによって、抽出できる要素や情報が異なります。
それに対してモデルは、プリプロセッサで抽出した画像や情報から新しい画像を出力できます。
アップデートで「Control Type」を選択すると、自動的にそれに合うプリプロセッサとモデルが指定されるようになりました。
複数プリプロセッサがある場合は手動で切り替えが必要ですが、基本は「Control Type」で使いたい機能をチェックすればそのまま使用が可能です。

ControlNetで使用できるプリプロセッサと対応モデル一覧
ControlNetで使用できるプリプロセッサとモデルをご紹介します。
こちらは23年5月時点の「v1.1.189」のものになります。新しいバージョンでは別の機能やプリプロセッサなどが追加されています。
ControlNetはWeb UIの画面左下の「ControlNet」という項目から操作できます。

クリックすると専用のUIが表示されるので、Enbleにチェックを入れて有効化します。

あとは画像を取り込んでプリプロセッサとモデルを選択すれば、それに基づいて情報を抽出したり、画像生成を行ったりできます。
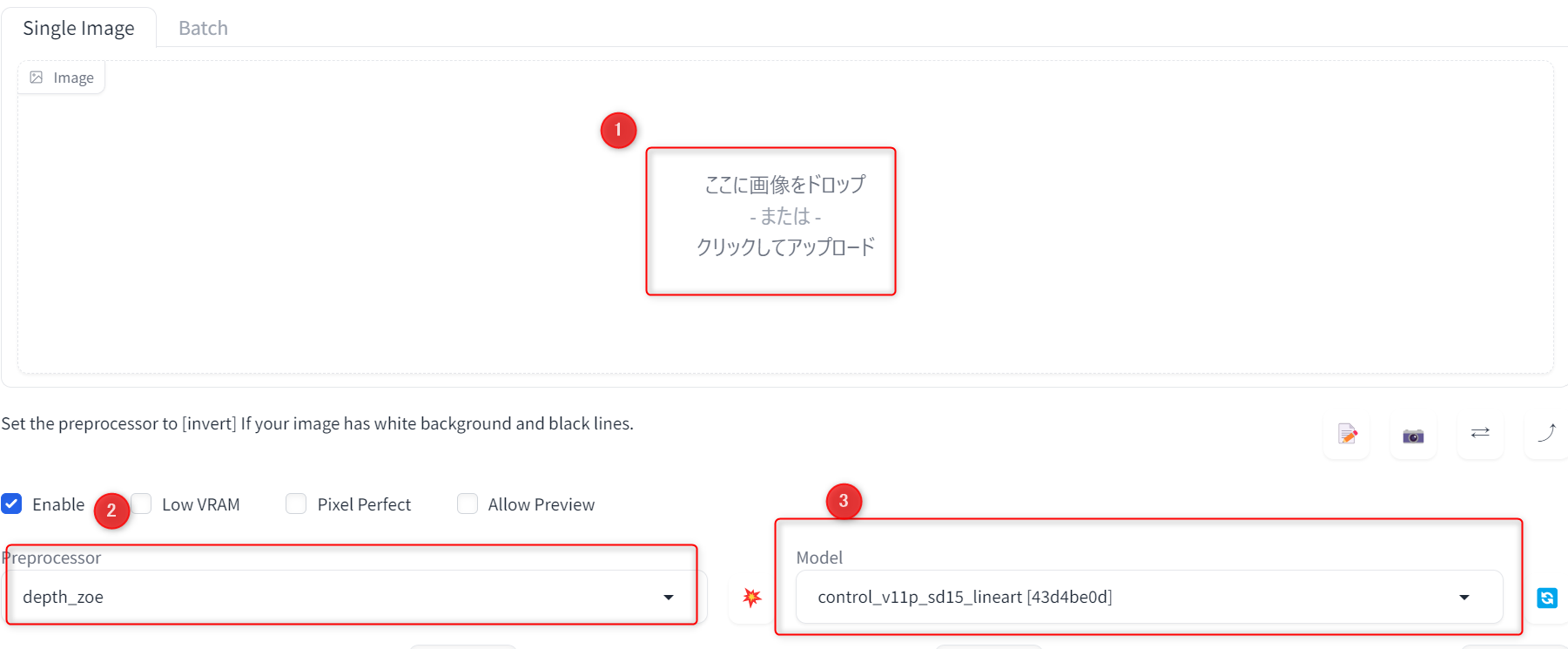
invert (from white bg & black line)(反転)
元画像が白背景+黒線画の場合に使用できるプリプロセッサです。
「lineart_standard (from white bg & black line)」という似た機能もありますが、invertは色を反転して画像を生成するので、線画が背景に溶け込むような印象になります。
白背景・黒線画を使ってプリプロセッサをinvert、モデルをlineart・lineart_animeにすると、以下のようになります。



- control_v11p_sd15_lineart
- control_v11p_sd15s2_lineart_anime
canny(エッジ検出)
cannyはエッジ検出という画像処理で、明暗の境界を検出できるプリプロセッサです。
lineartと似ていますが、lineartは主要な線や輪郭を強調するのに対して、cannyは明暗の境界を検出します。
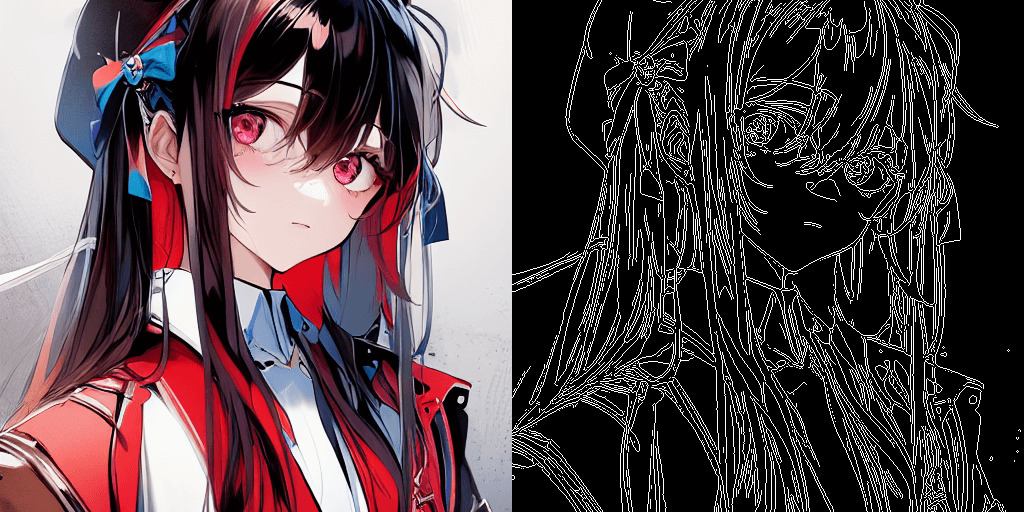
抽出したcannyでred hairと入れて画像生成すると以下のようになります。

control_v11p_sd15_canny
cannyで設定できるオプション
・Canny Low Threshold
cannyの低いしきい値を設定できます。
低くするとより弱いエッジを検出してエッジの量が多くなり、高くすると強いエッジのみ抽出するためエッジの量が減少します。
・Canny High Threshold
Cannyの高いしきい値を設定できます。
低くするとより多くのエッジを最終的なものとして確定するため、エッジの量が増えます。
高くするとより強いエッジを最終的なものとして確定するため、エッジの量が減少します。
depth~(深度)
depthは画像から深度マップを抽出できるプリプロセッサです。
奥行や距離情報を把握して、立体感のある画像が生成できます。
こちらは4種類のdepthで抽出した深度マップを比較したものです。





それぞれの深度マップからtokyoと入れて画像を生成すると以下のようになります。




control_v11f1p_sd15_depth
depthで設定できるオプション
Remove Near %
深度マップの手前にある被写体や物体を削除できる機能。
Remove Background %
深度マップの奥にある被写体や物体を削除できる機能。
inpaint(画像の補間・修正)
画像の一部を補間・修正できるプリプロセッサです。
冒頭で表情を変えましたが、画像の一部が削除・欠損している部分を周囲になじませて修正もできます。
まずinpaintを使用したい画像をドラッグで取り込みます。

次に補間・修正したい部分をペンでなぞり、マスクをかけます。
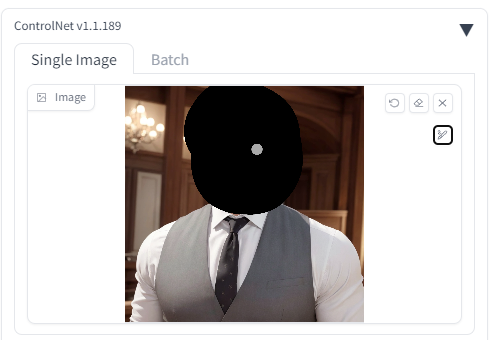
小さいですが右側にあるアイコンからペンの太さを変えられます。
アイコンは矢印が1つ前の手順に戻る、消しゴムが塗りを全部削除、×は画像を削除です。
プリプロセッサは「inpaint_only」と「inpaint_global_harmonious」の2種類存在します。
マスクをかけた部分のみ変更したい場合は「inpaint_only」、マスクをかけた部分と全体の色合いを変化させたい場合は「inpaint_global_harmonious」を使用します。
どちらかを選択してモデルを「control_v11p_sd15_inpaint」すると、塗りつぶした部分が周りの情報に合わせて、補間・修正されます。


画像生成時にプロンプトを入力すれば塗りつぶした部分に対して、プロンプトの要素を反映できます。


また以下のように一部欠損しているような画像も修正が可能です。

使い方は同じで、修復したいところにマスクをかけて画像生成をします。

inpaint_onlyはマスクをかけた部分のみ、inpaint_global_harmoniousだと修正+全体の色合いが変化します。


control_v11p_sd15_inpaint
lineart(線画)
lineartは線画を抽出できるプリプロセッサです。
lineartには3種類あり、それぞれのプリプロセッサで線画を抽出するとこのようになります。
lineart_standard (from white bg & black line)は元画像が白背景+黒線画のときに使うプリプロセッサです。
※lineart_standardだけ手動で反転させました




モデルをlineartにして画像を生成すると以下のようになります。プロンプトはそのままです。



control_v11p_sd15_lineart
lineart_anime(線画)
lineart_animeも線画を抽出できるプリプロセッサです。
名前の通りアニメのようなイラストを表現できます。
denoiseは通常よりノイズが強く除去されます。




- control_v11p_sd15s2_lineart_anime
mediapipe_face(顔の特徴検出・推定)
mediapipe_faceは顔の特徴を検出・推定できるプリプロセッサです。
mediapipe_faceのモデルは別途ダウンロードする必要があります。
下記URLにある「control_v2p_sd15_mediapipe_face.safetensors」というファイルです。

mediapipe_faceで画像生成すると、元画像の顔の特徴を維持して新しい画像が生成できます。


mediapipe_faceで設定できるオプション
Max Faces
被写体が複数人いるときに検出する顔の最大数を指定します。
Min Face Confidence
これは顔検出の信頼度の閾値を設定できるものです。
値を高くすると元画像と信頼度の高い顔のみ抽出します。
control_v2p_sd15_mediapipe_face
mlsd(直線検出)
mlsdは直線を検出できるプリプロセッサです。
部屋や建物の構造やレイアウト、距離などを抽出して新しい画像が生成できます。


プロンプトを変えると、レイアウトや家具の配置を維持したまま新しい画像が生成できます。



control_v11p_sd15_mlsd
normal(法線マップ)
normalは法線マップを抽出できるプリプロセッサです。
法線マップは元の画像から凹凸や光や影、物体の質感などを表現できるものです。
テクスチャマッピングやビジュアルエフェクトなどの分野でよく使用されます。



それぞれ銅や木のプロンプトで画像を生成してみました。


control_v11p_sd15_normalbae
openpose(ポーズ推定)
openposeは画像からポーズ推定を行い、身体の主要な部位などを検出できるプリプロセッサです。
openposeはそれぞれ特定の部位ごとに抽出できるプリプロセッサがあります。
openpose(体の部位を検出)

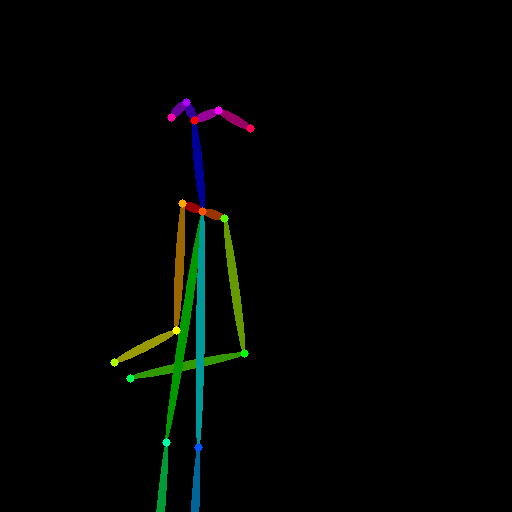

openpose_face(体と顔を検出)



openpose_faceonly(顔のみ検出)



openpose_full(顔・体・手など全て検出)

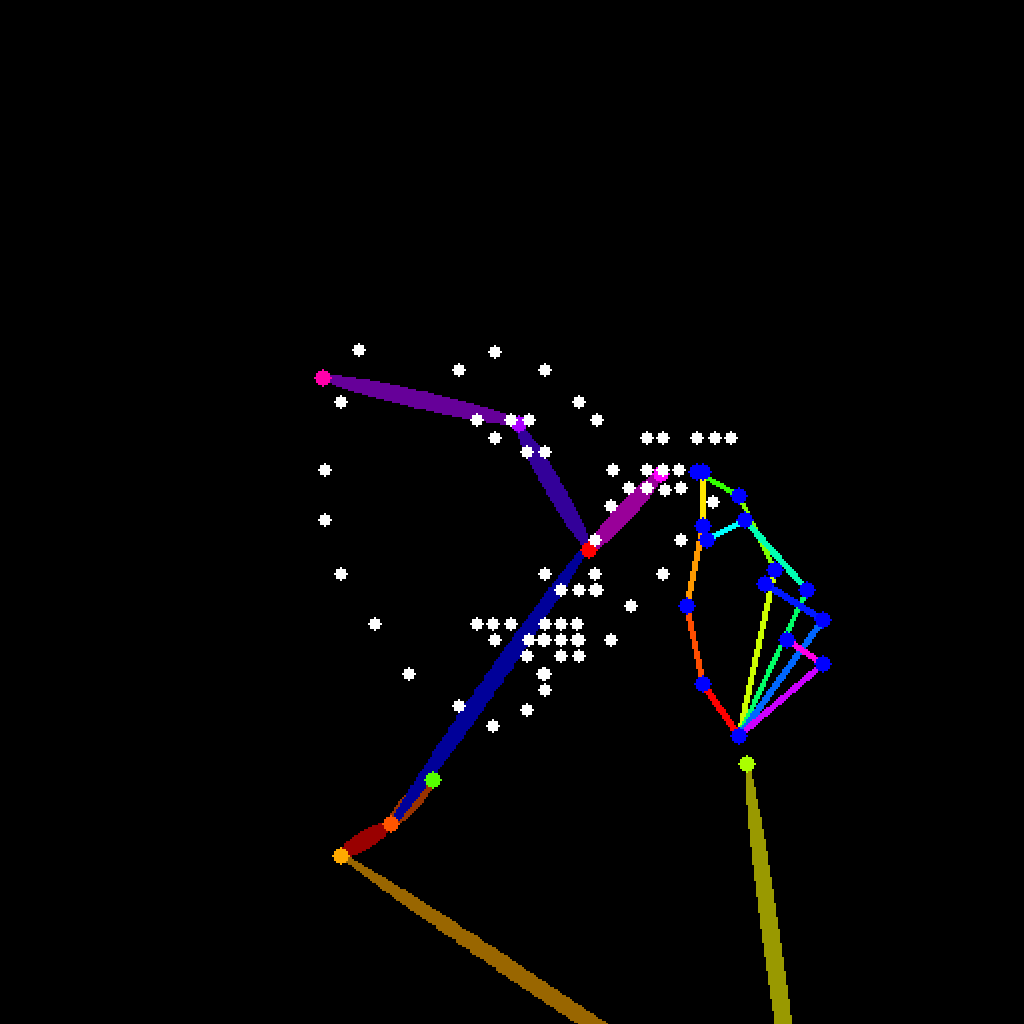

openpose_hand(体と手を検出)


control_v11p_sd15_openpose
reference
referenceはモデルなしで使えるプリプロセッサです。
簡易版LoRAのようなもので、元画像のスタイルや特徴とプロンプトを合わせて、総合的な生成結果を出します。
3種類のプリプロセッサがあり、それぞれで画像を生成するとこのような感じです。




referenceで設定できるオプション
Style Fidelity (only for "Balanced" mode)
Control ModeがBalancedのときのみ有効な機能です。
直訳するとスタイルの忠実度なので、特徴やテクスチャをどれだけ忠実に再現するか制御するものだと思います。
black hair,red eyesと入れて値を比較してみました。






なし
scribble
scribbleは画像から大まかなアウトラインが抽出できる機能です。
直訳すると「らくがき」なので元画像から構図を真似して再生成したり、下書きやラフ画を完成させたりといった使い方が効果的かもしれません。
元画像からそれぞれのscribbleで抽出すると、このようになります。

scribble_hed


scribble_pidinet


scribble_xdog


xdogのみ「XDoG Threshold」というパラーメータが表示されます。
これは閾値を設定できるもので、値を変更すると検出するエッジの強度や厚さなどを調整できます。
control_v11p_sd15_scribbl
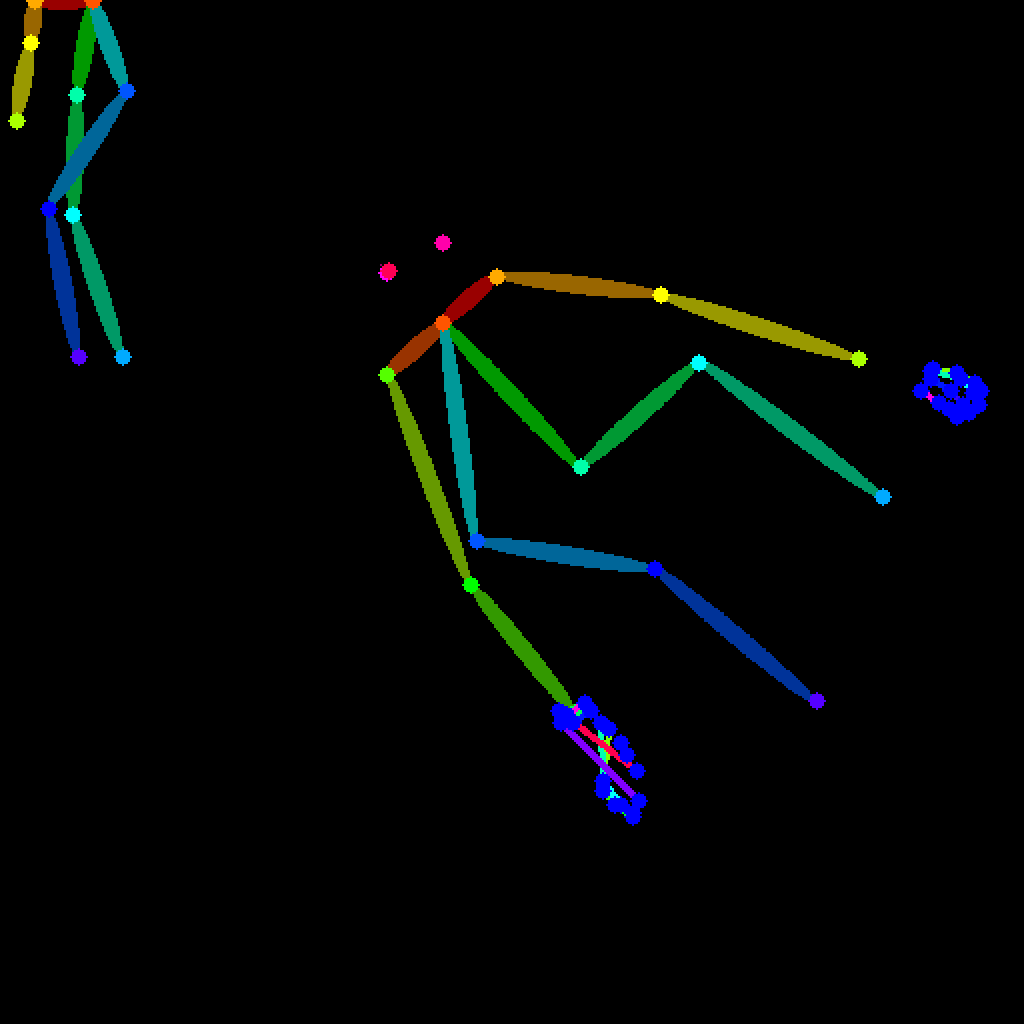
seg(セグメンテーション)
segはSegmentation(セグメンテーション)の略称で、画像からオブジェクトを識別して領域を分割できるプリプロセッサです。
プロンプトでうまく情報を与えると、オブジェクトを置換したり、背景を変更したりできます。

seg_ofade20k


seg_ofcoco


seg_ufade20k
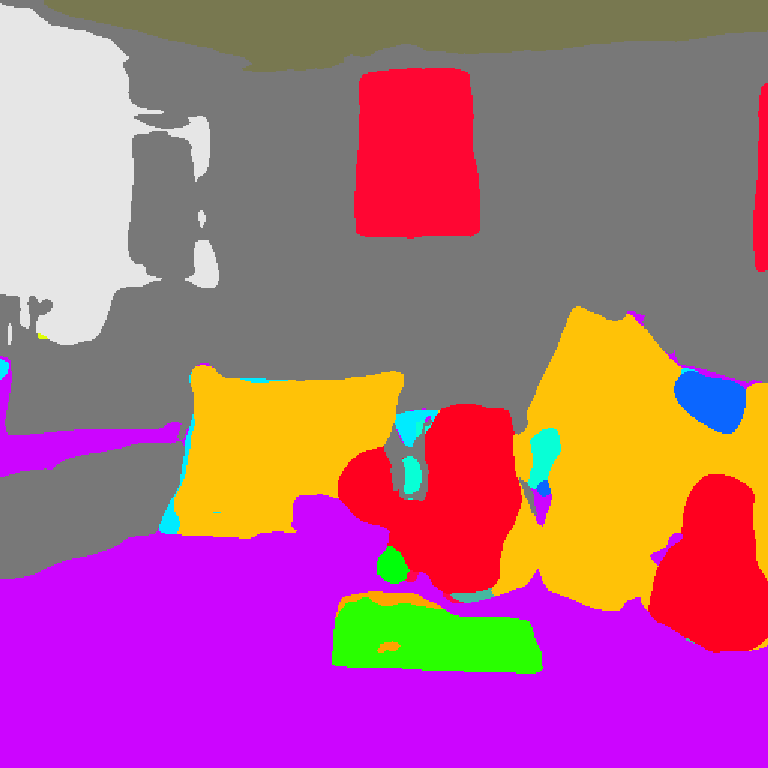

control_v11p_sd15_seg
shuffle
shuffleは取り込んだ画像を元に、プロンプトの要素を合わせて再構築できるプリプロセッサです。
referenceと似ていますが、shuffleは要素をランダムに変化させるので、より多様性のある画像が生成できます。



control_v11e_sd15_shuffle
softedge(ソフトエッジ領域)
画像からソフトエッジ領域を抽出できるプリプロセッサです。
cannyははっきりとした境界線を抽出しますが、softedgeは境界の滑らかな遷移やぼかし効果を表現する領域を抽出します。
境界線がより滑らかになることで、背景と被写体がなじみ、自然な画像を生成できます。

softedge_hed


softedge_hedsafe


softedge_pidinet


softedge_pidisafe


control_v11p_sd15_softedge
t2ia(T2I-Adapter)
t2iaはT2I-Adapterのことで、txt2imgに追加できる機能やモジュールなどを指します。
T2I-Adapterの機能を使用するには、それぞれ以下のモデルが必要です。
- t2iadapter_color_sd14v1.pth
- t2iadapter_sketch_sd15v2.pth
- t2iadapter_style_sd14v1.pth

t2ia_color_grid
これは元画像をグリッド(モザイク)にして、それぞれのピクセルから色情報を抽出できるプリプロセッサです。
プロンプトで生成する画像に対して、取り込んだ画像の色情報を反映できます。


t2iadapter_color_sd14v1
t2ia_sketch_pidi
これはスケッチのような大まかな線画を抽出できるプリプロセッサです。



t2iadapter_sketch_sd15v2
t2ia_style_clipvision
こちらは画像のスタイル情報(色合い・テクスチャなど)を抽出して、画像に反映できるプリプロセッサです。



t2iadapter_style_sd14v1
threshold
thresholdは画像を黒白で二値化するプリプロセッサです。境界や輪郭を白黒で抽出できます。

なお、threshold専用のモデルがないため、モデルの選択基準がよくわかりませんでした。
linesrtやcannyで出力すると以下のようになります。

thresholdで設定できるオプション
Binarization Threshold
黒白のバランスを調整できるオプションです。
デフォルトは127で値を下げると白、上げると黒の割合が増えます。


不明
tile
これは取り込んだ画像の解像度をタイル(ピクセル)ごとに変化させて、再度サンプリングできるプリプロセッサです。
tile_resample
tile_resampleは主に解像度に影響を与えます。
小さい画像やぼやけた画像を高解像度化したり、元の画像に変化を与えたりできます。



Down Sampling Rate
サンプリングの前にどれくらい解像度を下げるか指定できる値です。
値が多きいほど解像度が下がり、生成される画像もより変化が大きくなります。
・値による解像度の変化




・上記の解像度から生成した結果




tile_colorfix,tile_colorfix+sharp
23年5月26日に新しく「tile_colorfix」と「tile_colorfix+sharp」が追加されました。
tile_colorfixでは色味を調整でき、tile_colorfix+sharpは色と鮮明さを調整できます。



tile_colorfixではVariationというスライダーで色の変化量を調整できます。
tile_colorfix+sharpではVariationとSharpnessで色と鮮明さの調整が可能です。
control_v11f1e_sd15_tile
ip2p(指示プロンプト)
これはモデルのみで使用できる機能です。
説明プロンプトと指示プロンプト50%ずつ学習されたモデルで、「〇〇して」のような指示プロンプトを与えることで、取り込んだ画像に対してその要素を加えることができます。




control_v11e_sd15_ip2p
detected mapのみ生成する方法
プリプロセッサで情報を抽出した画像をdetected mapと呼びます。
プリプロセッサとモデルの間にあるアイコンをクリックするとdetected mapのみ生成できます。

プレビュー画面に表示され、右上の矢印アイコンでダウンロード、またはドラッグしてUnitにセットすることも可能です。

ControlNetで使用できるオプション
ControlNetで使用できるオプションについて解説します。
・Low VRAM
チェックを入れるとVRAMの消費量を下げられます。
公式だと8GB GPUを使用している方に対して、チェックを入れることを推奨しています。
ただし、チェックの有無で微妙に結果が異なります。
以下は同じ画像をTileでリサンプルしたもので、左がチェックなし、右がチェックありです。

・Pixel Perfect
チェックを入れるとプリプロセッサで抽出される画像の解像度が、元画像の解像度で維持されます。
・Allow Preview
チェックを入れるとプリプロセッサで抽出された画像をプレビューできます。
・Control Weight
ControlNetの影響量を調整できるオプションです。
・Starting Control Step/Ending Control Step
ControlNetを適用させる範囲を指定できます。
Starting Control Stepを0.2、Ending Control Stepを0.8にした場合、画像生成の工程のうち20~80%までControlNetが適用されます。
・Preprocessor Resolution
プリプロセッサで抽出される画像の解像度を変更できます。
Pixel Perfectにチェックが入っている場合は、このパラメータは無効になります。
・Control Mode
CFG scaleのようにプロンプトとControlNet、どちらの要素を重視するか選択できます。
公式の画像では以下のように変化しています。

・Resize Mode
取り込んだ画像と設定している解像度のサイズが違うとき、リサイズする方法を設定できます。
- Just Resize
- 全体が収まるようにリサイズ
- Crop and Resize
- 一部カットしてリサイズ
- Resize and Fill
- リサイズしてできた余白は塗りつぶす
・[Loopback] Automatically send generated images to this ControlNet unit
画像をセットせず、生成した画像を取り込んで、ControlNetの処理ができる機能です。
例えばLoopbackにチェックを入れて、画像をセットせずにtileを使用すると、生成した画像に対してtile処理が行われます。
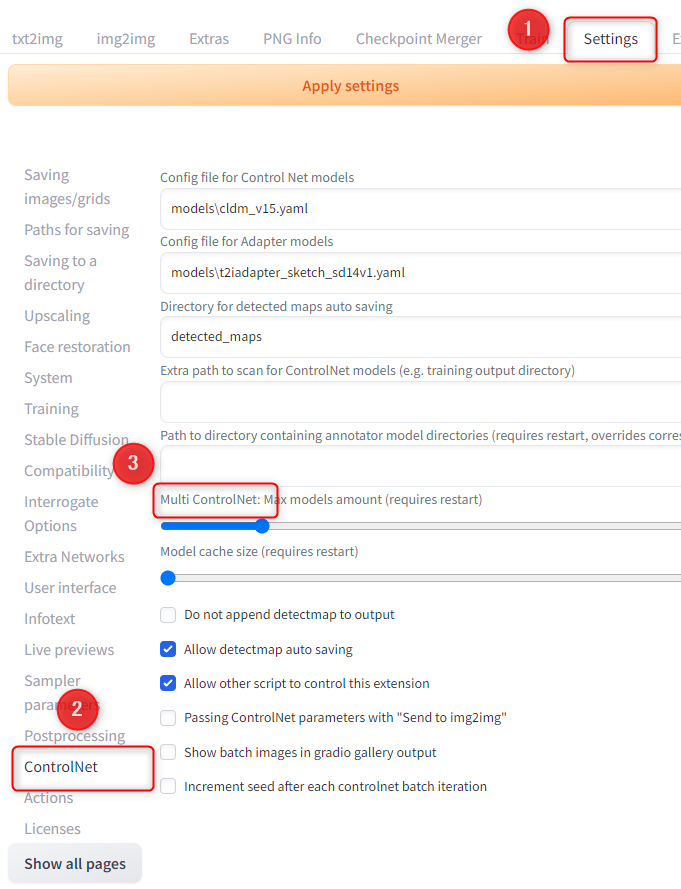
Multi ControlNet
これはControlNetを複数組み合わせて使える機能です。
Multi ControlNetを使うには「Setting」→「ControlNet」→「Multi ControlNet」の値を変更します。
今回は2にします。
設定した値と同じ数だけUnitタブが増えます。
例えばUnit0の方に炎の画像をセットしてスタイル情報を抽出します。
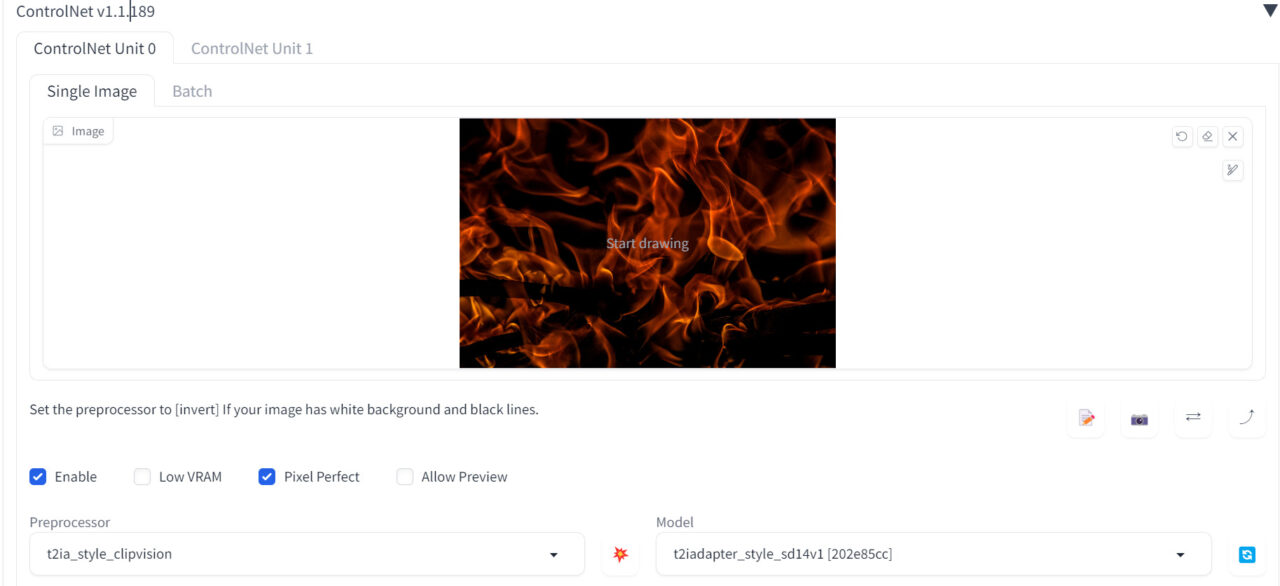
- プリプロセッサ:t2ia_style_clipvision
- モデル:t2iadapter_style_sd14v1
Unit1の方にはバイクの画像をセットして、cannyでエッジ検出をします。
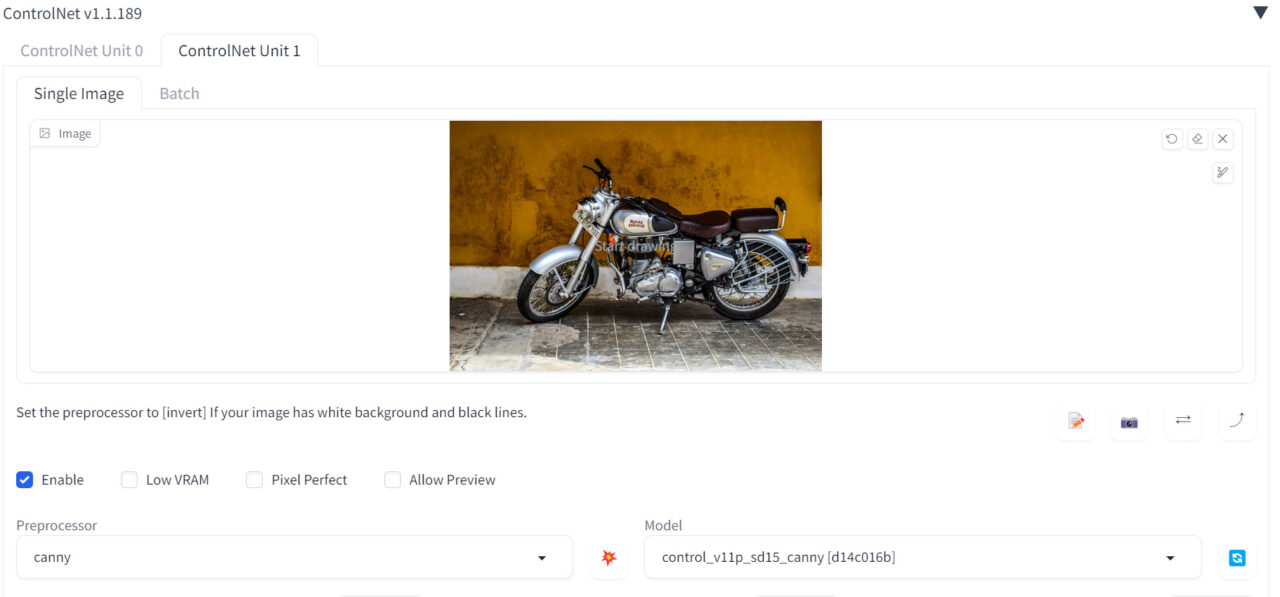
- プリプロセッサ:canny
- モデル:control_v11p_sd15_canny
こうするとUnit0のスタイル情報がUnit1で生成される画像に適応されます。

さらにプロンプトの要素も加えられます。
上記に加えてblue fireと入れたら以下のようになりました。

このようにプリプロセッサで抽出した情報を組み合わせられるのがMulti ControlNetです。
最大10個まで増やせますが、その分計算量も多くなるので注意してください。
ControlNetで発生したエラー
t2iaを使用したときに以下のエラー表示され、動きませんでした。
RuntimeError: Expected 3D (unbatched) or 4D (batched) input to conv2d, but got input of size: [257, 1024]調べてもエラーの意味はわからなかったのですが、原因はt2iaに対応するモデルを使っていなかったからです。
対応するモデルをインストールしたところ、エラーは発生せず問題なく動作しました。
また同じエラーが出ている方もいるので、こちらの記事も参考になるかもしれません。

https://github.com/pkuliyi2015/multidiffusion-upscaler-for-Stable Diffusion Web UI/issues/11
ControlNetを使用するときの注意点
ControlNetは非常に便利な機能ですが、OpenPoseなど一部商用利用不可のものがあります。
ライセンス取得が有料で、OpenPoseを使用した画像を商用利用することはできません。

使用範囲はプリプロセッサやモデルによって異なるため、公式ページのライセンスなども合わせて確認してください。
Stable Difussion Web UIでControlNetを使う方法まとめ
今回はStable Difussion Web UIでControlNetを使う方法について解説しました。
- ControlNetって何ができるの?
- Stable Difussion Web UIにControlNetをインストールする方法
- ControlNetのモデルをダウンロードする方法
- ControlNetの基本的な使い方
- ControlNetで使用できるプリプロセッサとモデル一覧
- ControlNetで使用できるオプション
- ControlNetで発生したエラー
ControlNetが使えると本当にいろいろな画像生成ができます。
画像の修正や高解像度化、ポーズの指定、再構築など、出来ないことがないレベルです。
実用的な画像を生成するならControlNetは必須といっても過言ではないので、ぜひ使ってみてください。
なお、SDXLを使うならControlNetの作者さんが作ったFooocusというUIも便利です。


