
先日リリースされたforgeに標準でSVD(Stable Video Diffusion)が搭載されていました。
ComfyUIもSVDに対応していたので、今回はそちらの使用方法についてご紹介します。
ComfyUIでSVDで使う方法
SVDは画像一枚から動画が生成できる技術です。
ComfyUIでは、モデルとワークフローを導入するだけで、簡単に動画を作ることができます。
ComfyUIのインストール
まだComfyUIのインストールをしていない方は、事前にインストールが必要です。
インストール方法は簡単で、公式サイトからzipをダウンロードし、中にある「run_nvidia_gpu.bat」を起動するだけです。
以下リンクの「Direct link to download」からダウンロードできます。
詳細はこちらの記事もご確認ください。

SVDモデルのダウンロード
SVDを使用するには、SVDのモデルが必要です。
以下のリンクから「svd.safetensors」をダウンロードしてください。
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/tree/main
通常のモデルを置いているパスに移動させます。
・Stable Diffusion Web UIから取り込んでいる場合
stable-diffusion-webui\models\Stable-diffusion・ComfyUIに直接モデルを置いている場合
ComfyUI_windows_portable\ComfyUI\models\checkpointsSVD用ワークフローの導入
次にSVD用のワークフローを導入します。
公式にサンプルがあるので、そのまま画像をComfyUIにD&Dしてください。
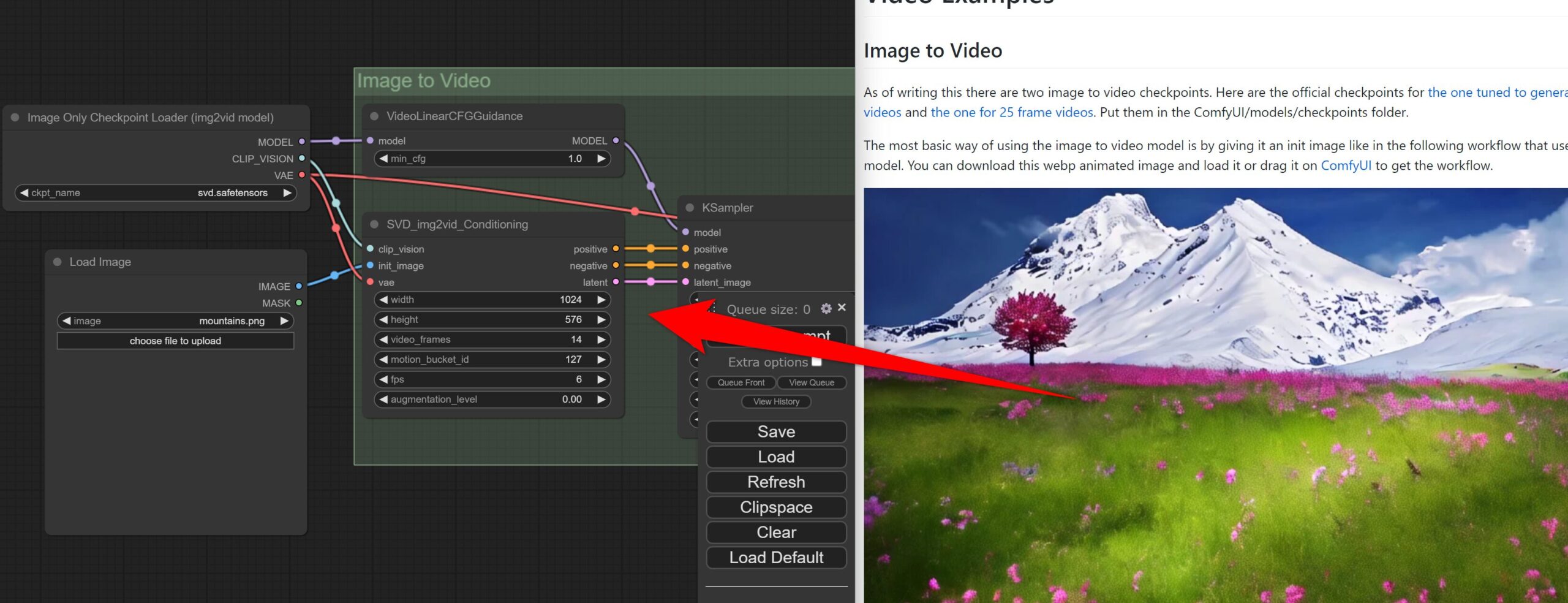
https://comfyanonymous.github.io/ComfyUI_examples/video/
そうするとSVDを使用するためのノートが追加されるので、「Load image」に画像を取り込みます。

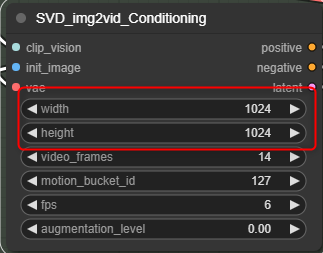
SVD_img2vid_conditioningで取り込んだ画像とサイズを同じにしてください。
これで「Queue prompt」をクリックすれば、取り込んだ画像から動画生成されます。
なお、元画像によってかなりクオリティが異なります。
人物の肖像画みたいな画像だと、背景が動くだけであまり変化がありません。
景色や動きが予測できるようなものだと綺麗に生成できますが、人が走っている様子などは結果がいまいちでした。
三次元・二次元でも結構変わるので、いろいろ試してみてください。
SVDのパラーメータについて
パラーメータを変化させることで、動画の結果にも影響があります。
forgeの記事で書いたものとほぼ同じですが、ノードごとに設定できるパラメータは以下の通りです。
・VideoLinearCFGGuidance
Min Cfg - 最初のCFG
・SVD_img2vid_conditioning
width - 画像の横幅
height - 画像の縦幅
video_frames - 動画の長さ
Motion Bucket Id - 含まれる動きの量
Fps - 1秒間に使用する画像枚数
Augmentation Level - 追加されるノイズの量値が大きいと動きが増加するが、元画像の変化も多くなる
・KSampler
Seed - シード値(変更すると動画も少し変化します)
Control after generate - シード値をどう変化させるか
steps - 生成の工程を何ステップで行うか
cfg - 最後のCFG
Sampler Name - 使用するサンプラー
Scheduler - 使用するスケジューラー
Denoise - ノイズ除去強度
なお、具体的にどのパラーメータがどういう影響を与えるかについては、Redditで比較・解説している方がいるので、こちらも参考にしてみてください。
Stable VIde Diffusion motion bucket id comparison : r/StableDiffusion
ComfyUIでSVD(Stable Video Diffusion)を使う方法まとめ
今回は、ComfyUIでSVDを使う方法についてご紹介しました。
単純に画像1枚から動画を作れるという技術がすごいので、さまざまな画像を試すだけでも楽しめるかと思います。
現時点で実用的な使い方はちょっと浮かびませんが、興味ある方は使ってみてください。
