
23年7月27日にStability AIからSDXL 1.0がリリースされました。
画像生成AI界隈で非常に注目されており、既にStable Diffusion Web UIで使用することが可能です。
この記事ではSDXLをStable Diffusion Web UIで使用する方法や、使用してみた感想などをご紹介します。

Stable Diffusion XL(SDXL)とは?
Stable Diffusion XL(SDXL)は、Stability AIが新しく開発したオープンモデルです。
ローカルでStable Diffusion Web UIを使用している方は、デフォルトでv1.5やv2.1などのモデルが導入されていたと思います。
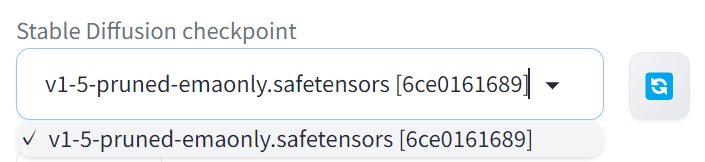
これがStable Diffusionで使用できるStability AIの基本モデルで、このモデルの最新バージョンが今回リリースされたSDXLになります。
特徴としては、今まで難しかった手や空間的な配置の構造が生成しやすくなっており、高画質にする「masterpeace」などのプロンプトが必要ないとのことです。
・公式サイトのリリース
https://ja.stability.ai/blog/sdxl10
・動画
SDXLをclipdrop.coで体験する
SDXLを今すぐ体験したい方は、clipdropというWebアプリで試すことができます。
無料だと画像にウォーターマークが入り、生成枚数にも制限がありますが、手軽にSDXLが体験できます。
以下のサイトにアクセスし、プロンプトを入力してGenereteをクリックするだけです。
https://clipdrop.co/stable-diffusion
今回は「異世界の森で戦う男性(A man fighting in a forest in another world)」と入力してみました。

入力欄の隣にあるアイコンから、スタイルや画像サイズなどを指定できます。

設定が終わったらGenerateをクリックします。

有料プランに加入すると待ち時間を短縮できますが、skipで無料のまま利用が可能です。
生成が終わると4枚の画像が生成され、クリックで確認することができます。
実際に生成した画像がこちらです。(1枚保存できていませんでした。)



Stable Diffusion XL(SDXL)をStable Diffusion Web UIに導入する方法
SDXLをStable Diffusion Web UIで使用するには、以下の手順が必要です。
- Stable Diffusion Web UIをアップデート
- コマンドライン引数の設定
- SDXLのモデル・VAEをダウンロード
Stable Diffusion Web UIのインストール方法は別記事で解説してるので、こちらを参考にしてみてください。

https://ikuriblog.com/how-to-use-stable-diffusion-web-ui-with-google-colab/
Stable Diffusion Web UIをアップデート
SDXLを使用するには、Stable Diffusion Web UIのバージョンを1.5.0以上にする必要があります。
アップデート方法は簡単で、Stable Diffusionのフォルダで「右クリック」→「ターミナルを開く」を選択し、コマンドで「git pull」を実行するだけです。

これでStable Diffusion Web UIは最新バージョンにアップデートされます。
モジュールなど依存関係の更新方法については、こちらの記事を参考にしてください。

コマンドライン引数の設定
コマンドライン引数は、Stable Diffusion Web UIを起動するときに設定できるオプションのようなものです。
Stable Diffusion Web UIのリリース情報に、SDXL使用時は「--no-half-vae」が必要と書かれています。
これはVAEで16ビットの浮動小数点演算を使用しない設定で、画像生成の精度が向上します。
またVRAMの使用量を抑える「--medvram」も機能するそうなので、VRAMが8GBの方はこちらも合わせて使用した方がいいかもしれません。
詳細はこちらを確認してください。
https://github.com/Stable Diffusion Web UI/stable-diffusion-webui/pull/11757
コマンドライン引数を設定するには、Stable Diffusionフォルダ内にある「webui-user.bat」を右クリック→編集で開きます。
テキストファイルが開くので、「set COMMANDLINE_ARGS=」の行に上記のコマンドを追加して保存します。

set COMMANDLINE_ARGS=--xformers --no-half-vae --medvramその他ダークモードにしたり、自動でブラウザを開いたりできるコマンドライン引数もあります。
githubで一覧を確認できるので、お好みで追加してください。
SDXLのモデルとVAEをダウンロード
次にSDXLのモデルとVAEをダウンロードします。
SDXLのモデルは2種類あり、基本のbaseモデルと、画質を向上させるrefinerモデルです。
どちらも単体で画像は生成できますが、基本はbaseモデルで生成した画像をrefinerモデルで仕上げるという流れが一般的なようです。
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
23年8月現在、Stable Diffusion Web UIはrefinerモデルに対応していないのですが、img2imgや拡張機能でrefinerモデルが使用できます。
ですので、SDXLの性能を全て体験してみたい方は、どちらのモデルもダウンロードしておきましょう。
Hugging Faceのサイトからダウンロードが可能です。
モデルのダウンロード
・baseモデル
以下のリンクから「sd_xl_base_1.0.safetensors」をダウンロードしてください。
矢印アイコンをクリックするとダウンロードできます。
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main

・refinerモデル
refinerモデルはこちらからダウンロードできます。
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main

ダウンロードしたモデルは、以下のパスに移動させておいてください。
stable-diffusion-webui\models\Stable-diffusionVAEのダウンロード
VAEはものすごく簡単にいうと、画像の品質や表現力が向上できるものです。
モデルと合わせて、SDXL用のVAEがリリースされています。
以下のリンクから「sdxl_vae.safetensors」をダウンロードしてください。
https://huggingface.co/stabilityai/sdxl-vae/tree/main
VAEは以下のパスに移動させます。
stable-diffusion-webui\models\VAEこれで準備は完了です。
Stable Diffusion XL(SDXL)モデルの使い方
SDXLを使用する準備が整ったので、実際にStable Diffusion Web UIで使用する方法について解説します。
なお、AUTOMATIC ver1.6.0からSDXLに対応しました。
デフォルトで使用できるようになっているため、ver1.6.0での使い方はこちらを参考にしてください。
Stable Diffusion XL(SDXL)モデルを使用する前に
SDXLモデルを使用する場合、推奨されているサンプラーやサイズがあります。
それ以外の設定だと画像生成の精度が下がってしまう可能性があるので、事前に確認しておきましょう。
| 推奨サイズ | 1024 x 1024 1152 x 896 896 x 1152 1216 x 832 832 x 1216 1344 x 768 768 x 1344 1536 x 640 640 x 1536 |
| サンプルステップ | 30-50 |
| CFG Scale | 4-14 |
| Sampler | ddim plms k_euler k_euler_ancestral k_heun k_dpm_2 k_dpm_2_ancestral k_dpmpp_2s_ancestral k_dpmpp_2m k_dpmpp_sde |
こちらのページで全て確認ができます。
https://platform.stability.ai/docs/features/api-parameters#about-dimensions
baseモデルで画像を生成
baseモデルは従来の使い方と一緒です。
checkpointをbaseモデル、VAEをSDXL用のものにして、プロンプトを入力後、Genereteをクリックします。

推奨サイズの1024*1024に設定して「ピースサインをして微笑む女性(Woman smiling with a peace sign)」と入力して生成してみました。

・生成時の設定とパフォーマンス
Woman smiling with a peace sign
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 3270369670, Size: 1024x1024, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, Version: v1.5.1
Time taken: 49.5 sec.
A: 5.08 GB, R: 12.03 GB, Sys: 8.0/8 GB (100.0%)手を生成しやすくなったと書かれていましたが、残念ながらこの設定だと指が崩れてしまいました。
またコマンドライン引数を設定してもRTX 3060 Ti(VRAM8GB)だと、消費量が100%となっており、かなりPCに負荷がかかっているのがわかります。
refinerモデルをimg2imgで使う方法
次に生成した画像をimg2imgに送り、refinerモデルを通してみます。
txt2imgで生成した画像の下にある「Send to img2img」をクリックすると、プロンプトやシード値をそのままimg2imgタブに送れます。
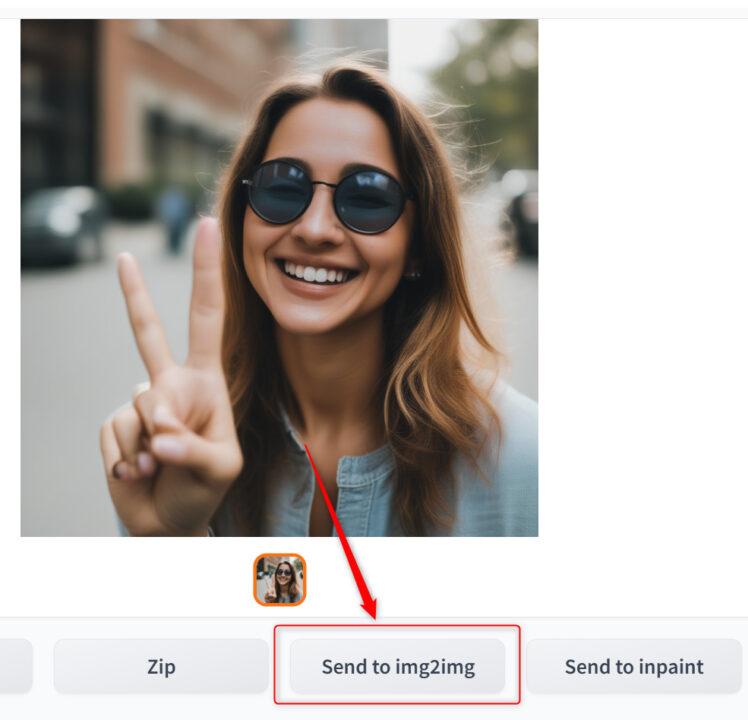
img2imgタブでモデルをrefinerモデルに変更してください。

なお、refinerモデルを使用する際、Denoising strengthの値が強いとうまく生成できないようです。
ですので、Denoising strengthの値を0.2~0.3に設定します。

左がbaseモデル、右がrefinerモデルを通した画像です。

refinerモデルを通した方が、肌や服の質感がよりリアルに描写できていると思います。
プロンプトやサンプラーなどを工夫すれば、もう少しクオリティの高い画像が生成できるかもしれません。
拡張機能でrefinerモデルを使う方法
Stable Diffusion Web UIでrefinerモデルを使用するための拡張機能があります。
こちらはtxt2imgだけで、baseモデルとrefinerモデルを使用することが可能です。
拡張機能のインストール
「Extensions」タブの「Install from URL」に行き、「URL for extension's git repository」に下記URLを入力して、「Install」をクリックします。
https://github.com/wcde/sd-webui-refiner.git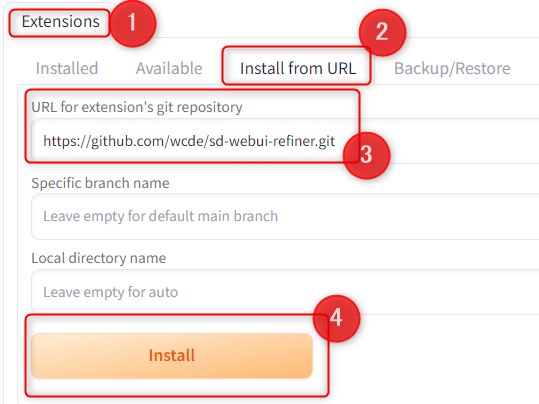
そうするとインストールが始まり、「Installed」タブに「sd-webui-refiner」が追加されます。

一度Stable Diffusion Web UIをリロード、または再起動してください。
これでインストールは完了です。
拡張機能の使い方
まずtxt2imgタブでcheckpointをbaseモデルにして、VAEもSDXL用にしてください。
次にseed値より下の方に「Refiner」という項目が追加されているので、「Enable Refiner」にチェックを入れ、modelはRefinerモデルを選択します。
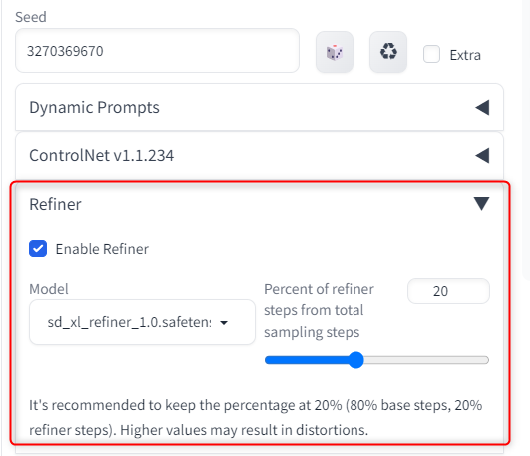
右側のsampling stepsは、全行程の何割にRefinerモデルを使用するか指定できる値です。
下の説明でbase80%、Refiner20%が推奨されているため、通常はデフォルトの20%で問題ありません。
この状態でプロンプトを入力し画像生成をすれば、txt2imgだけでbaseモデルとRefinerモデルを使用できます。
比較するために上記で生成した「ピースサインをして微笑む女性」を、拡張機能を通して生成してみました。
左からbaseモデルのみ、img2img、拡張機能を使った画像です。

やはりbaseモデルのみより、Refinerモデルを使用した方が画像のクオリティは高いです。
img2imgと拡張機能も質感に微妙な違いがあり、上記の画像ではimg2imgが一番綺麗かと思います。
ただし、これは値や設定によるものだと思うので、調整次第で結果を近づけられるかもしれません。
手間を考えると、拡張機能を使う方法が一番簡単に生成できます。
Stable Diffusion XL(SDXL)を使ってみた感想
試行回数はそこまで多くないのですが、現時点でSDXLを使ってみた感想です。
そこまで劇的な変化は感じられない
プロンプトの入力方法や設定もあるかもしれませんが、手の生成確率がそこまで上がったようには感じられませんでした。
「1girl,photo realstic, peace sign」で生成した画像


空間的な構図に関しては、従来のモデルでそういった画像を生成した経験が少ないため、あまり比較できていません。
「dog chasing cat」や「American city」で生成すると、このような結果になります。


動作が重い
単純にモデルの容量が大きいため、読み込みに時間がかかります。
また生成時間も他のモデルより長く、上記の「American city」に関しては2分以上かかりました。
生成する要素やプロンプトが多くなればなるほど、時間がかかってしまうかもしれません。
快適にSDXLを使用するのではあれば、ある程度PCスペックを揃える必要があります。
Stable Diffusion XL(SDXL)をStable Diffusion Web UIで使う方法まとめ
今回はSDXLをStable Diffusion Web UIで使う方法について、ご紹介しました。
- Stable Diffusion XL(SDXL)とは?
- SDXLをclipdrop.coで体験する
- Stable Diffusion XL(SDXL)をStable Diffusion Web UIに導入する方法
- Stable Diffusion XL(SDXL)モデルの使い方
- Stable Diffusion XL(SDXL)を使ってみた感想
まだ私自身が使いこなせていないため、もう少し勉強すれば思ったような画像が生成できるかもしれません。
最新モデルというだけあって界隈も盛り上がっており、Civitaiなどで既に対応しているLoRAやSDXLをベースにしたモデルなども配布されております。
導入自体はそこまで難しいものではないので、興味がある方はぜひ試してみてください。
